We (AASCU’s Digital Polarization Initiative) have a large information literacy pilot going on at a dozen institutions right now using our materials. The point is to gain insight into how to improve our instruction, but also to make sure it is working in the way we think it is. Part of that involves formal assessment which I am working on with Tracy Tachiera, my co-PI.
A few weeks ago we finished the Washington State classes in the pilot, in what we’re calling our high-fidelity implementation. For those unfamiliar with educational pilots I should note that that doesn’t mean the other implementations were worse or lower-value. It just means that since the materials were delivered by someone intimately familiar with how to deliver them (me) we have a high confidence that the intervention we are testing is what we think we are testing.
In any case, we have some of our first pre/post data in, on a decent implementation.
One important caveat to start: I am reporting here *only* on the four classes I taught directly. We have well over a thousand students in the multi-institutional pilot with something like 1,300 assessments already logged; it’s a big knotty, messy assessment problem that will take some time and money to finish. But what we’re seeing in the interim is important enough that reporting on the smaller group more immediately seemed warranted.
Rating Trustworthiness
So here’s the assessment directions the students got. They are pretty bland:
You will have 20 minutes total to answer the following four questions. You are allowed to use any online or offline method you would normally use outside of class to evaluate evidence, with the exception of asking other students directly for help.
You are allowed to go back and forth between pages, and can revisit these instructions at any time.
The students then took an A or B version of the test before the 4 hour intervention and the opposite test afterwards. The instruction was delivered in the classes over three weeks, with a three week gap after it before the post-assessment in order to capture skills decay. (Due to a scheduling conflict, one of the four classes received only 2 hours and 40 minutes of instruction, they are not included in the post-test data here, but their results were generally somewhere between the pre- and post-test results of the other classes).
Key to the assessment was we had a mixture of what we called “dubious” prompts, where a competent student should choose a very low or low level of trust (depending on the prompt), and trustworthy prompts, where competent students would rate it moderate or higher.
So, for example, this is a dubious prompt: a conspiracy story that has been debunked by just about everyone:

Our target for this is that the students rate trust in it “Very Low” due to information you can find quite easily on it (using our “check other coverage” move)
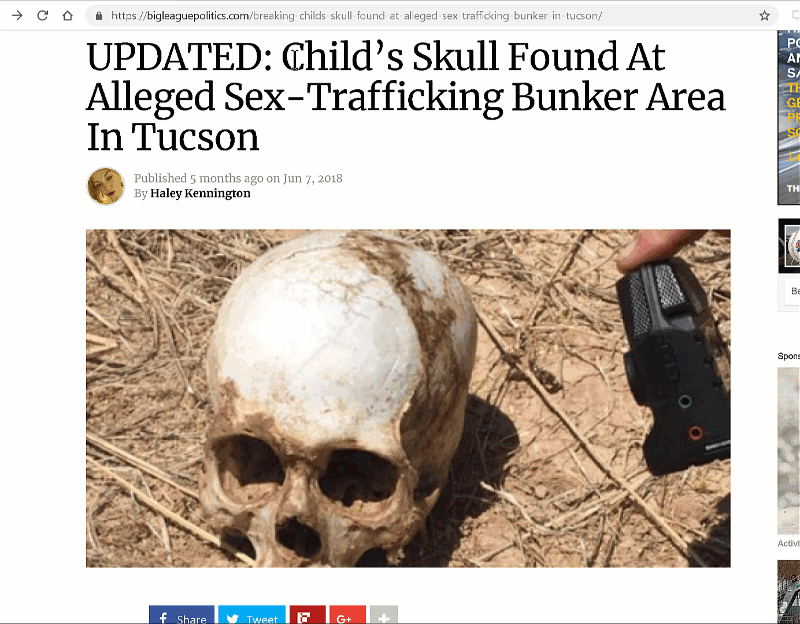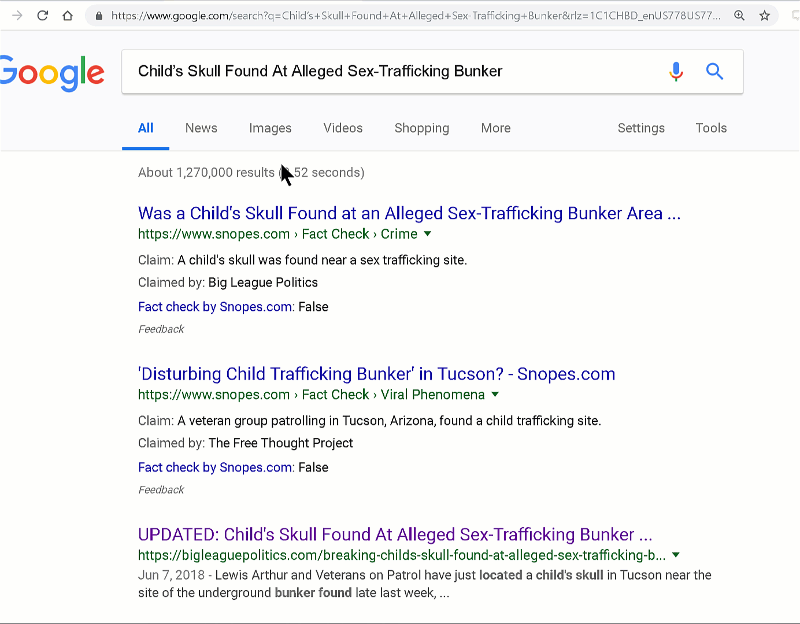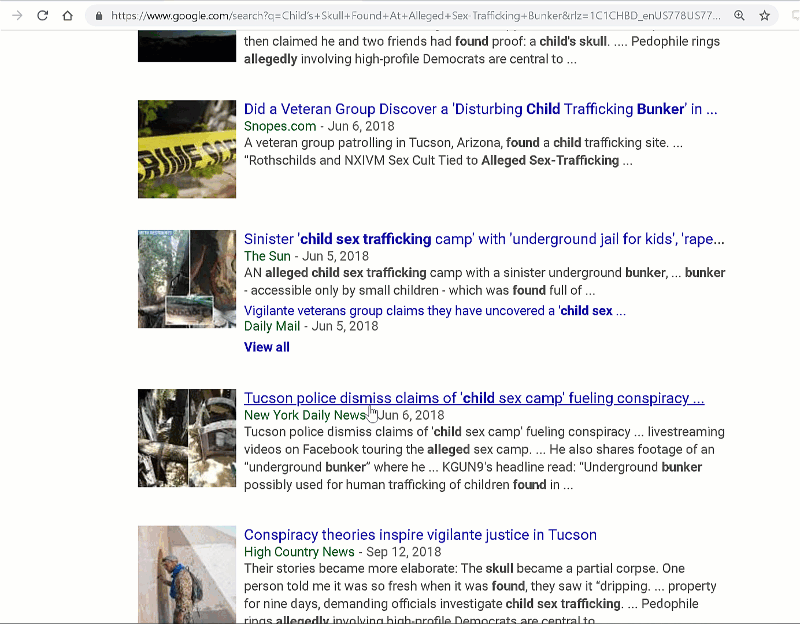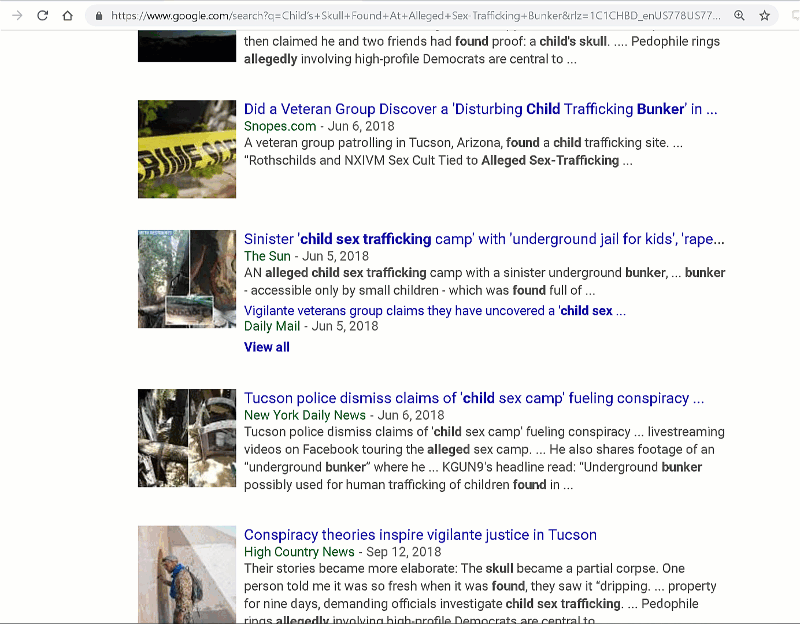
And here is a paired trustworthy prompt in the news story category (our other prompts are in photographic evidence, policy information, and medical information):
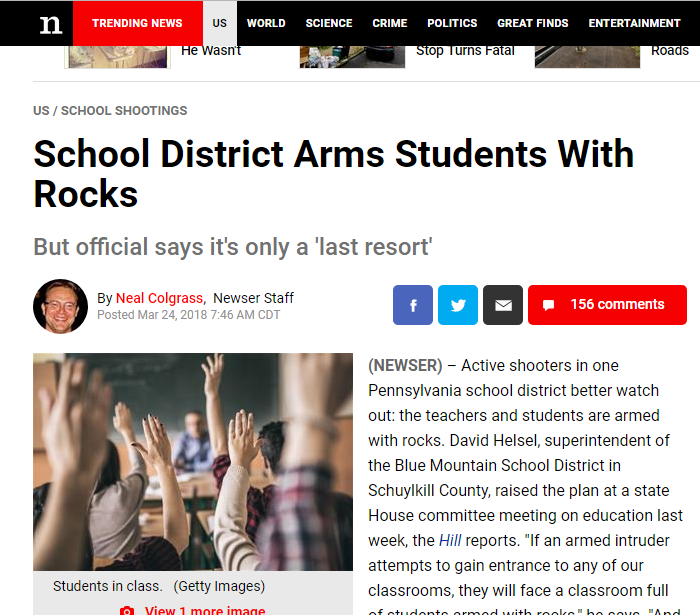
In the above case, of course, the story is true, having been reported by multiple local and national outlets, and supported by multiple quotes from school officials. We set the target on this as meriting high or very high trust. The story as presented happened, and apart from minor quibbling about the portrayal, a fact’s a fact.
As you can see, this is all rough, which is why we are ultimately more interested in the free text replies. People might mean different things by “high” or “very high”. Arguments could be made that a prompt we considered very low should be rated “low”. Students might get the answer right for wrong reasons. Scoring the free text will show us if the students truly increased in skill and helpful dispositions.
But even with this very rough data we’re seeing some important patterns.
Finding One: Initial Trust of Everything Is Low
First, students rate dubious prompts low before the intervention:
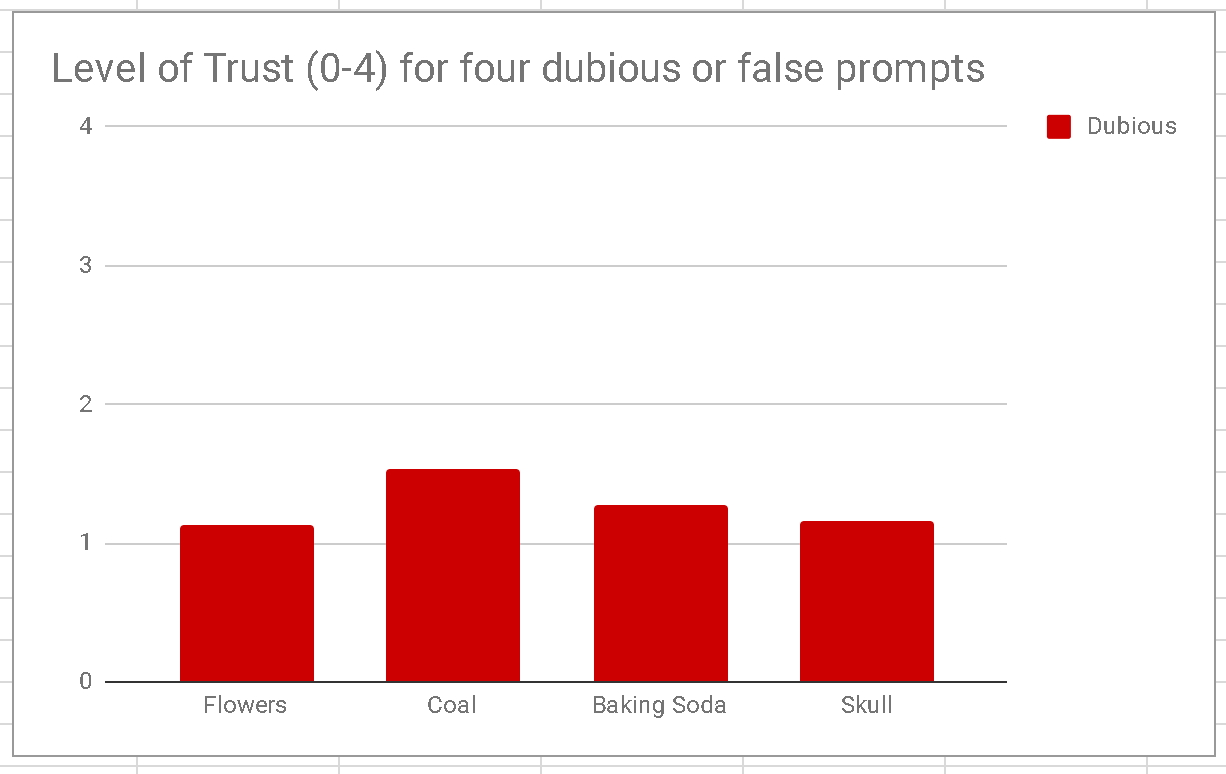
Great, right?
Yeah, except not so much. Here are the trust ratings on the trustworthy prompts right next to them in blue:
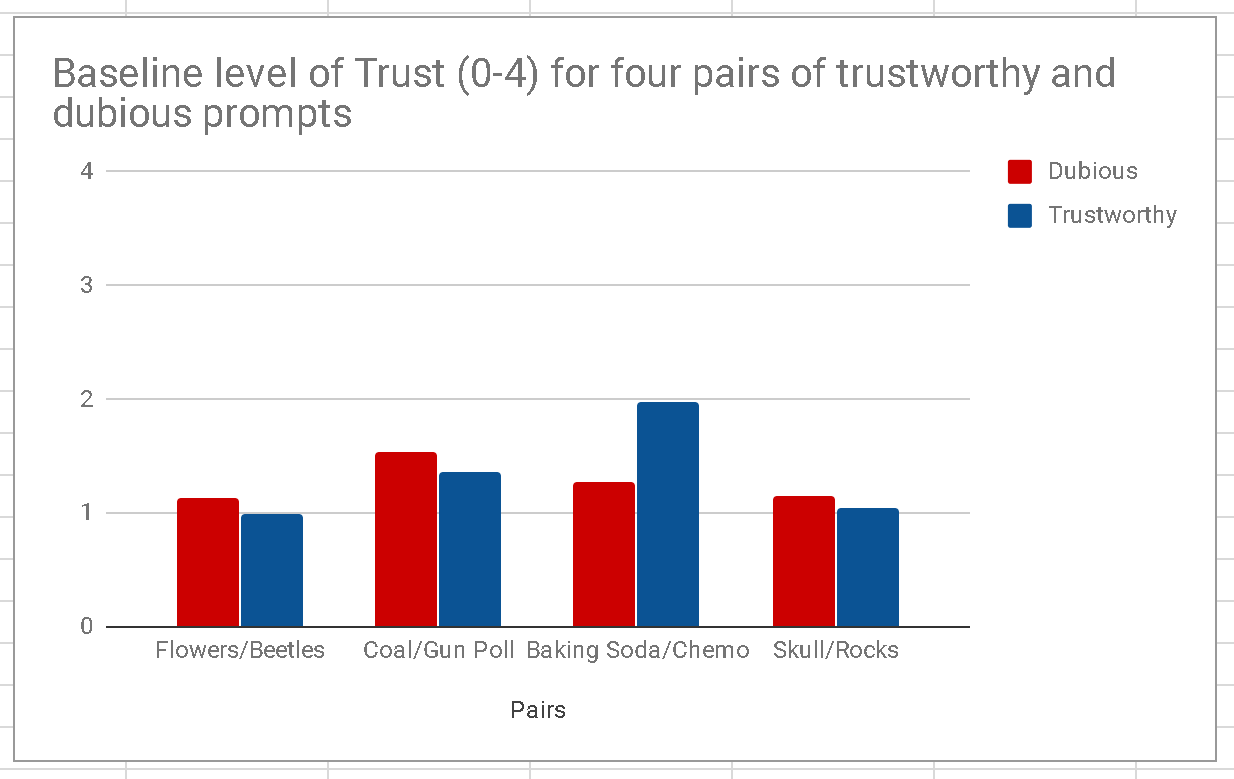
On average, students in our four WSU classes rated everything, dubious and trustworthy alike, as worthy of low to moderate trust.
This actually doesn’t surprise me, as it’s what I’ve seen in class activities over the past couple of years, a phenomenon I call “trust compression“. We’re looking to make sure that this phenomenon is not a result of subject headings around the prompts or student expectations around material but we expect it to hold.
Finding Two: After Instruction the Students Differentiate by Becoming Less Cynical
I was going to do a big dramatic run-up here, but let’s skip it. After the pre-test we did (in three of the classes) four hours of “four moves” style instruction. And here’s what trust ratings look like on the assessment after that 4 hours of instruction (these are raw results, so caveat emptor, etc):
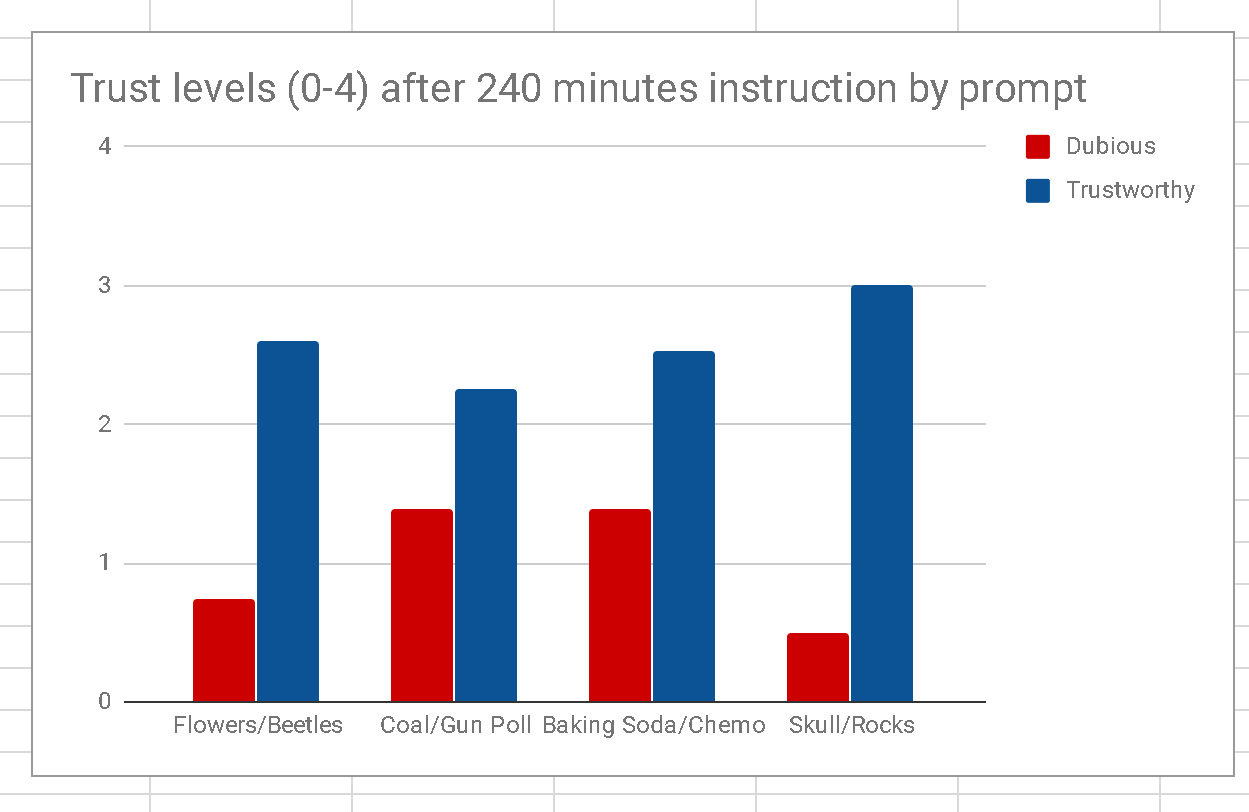
That’s the same y-axis there. You can see what is happening — the students are “decompressing” trust — rating trustworthy items more trustworthy and (with the exception of the baking soda prompt) dubious prompts more untrustworthy. The graph is a bit hard to read without understanding what an appropriate response is on each — on gun poll trust, for example, 2 is an acceptable answer — it’s a survey done by a trustworthy firm and in line with many other findings, but is sponsored by Brookings and pushed by the Center for American Progress, neither of which can be seen as neutral entities. The Chemo prompt is deserving of at least a three, and the rocks prompt should be between three and four. But the pattern seems clear –most of the gap opening up is from the students trusting trustworthy prompts *more*.
How the students do this is not rocket science of course. They become more trusting because rather than relying on the surface features and innate plausibility of the prompts they check what others say –Snopes, Wikipedia, Google News. If they find overwhelming consensus there or reams of linked evidence on the reliability of the source, they make the call.
(Potential) Finding Three: Student answers may be less tribal after intervention
Emphasis on may, but this looks promising. We have not gone deep into to the free answers, but an initial scan of them seems to indicate that students are less tribal in their answers. To be fair, tribalism doesn’t figure much into either pre- or post- responses. Fatalism about the ideological filters of older adults may be warranted, but at least on the issues we tested with our first years (including coal industry benefits, nuclear power risks, alternative medicine, gun control, and child sex-trafficking conspiracy) there was far less tribalism in evidence than current discussion would have you think.
Where there was tribalism it tended to disappear in the post-test, for an obvious reason. The students in the pre-test were reacting to the page in front of them, trying to recognize misinformation. In doing so, they fell back on their assumptions of what was likely true and what was not, usually informed by tribal understandings. If you stare at a picture mutated flowers and ask whether it seems plausible then your answer is more likely to touch on whether you believe nuclear power is safe or not. This is the peril of teaching students to try and “recognize” fake news — doing so places undue weight on preconceptions.
If, on the other hand, you look not to your own assumptions but to the verification and investigative work of others for an answer, you’re far less likely to fall back on your belief system as a guide. You move from “This is likely because I believe stuff like this happens” to “There might be an issue here, but in this case this is false.”
(Much) more to come
We have a lot of work to do on with our data. We need to get the WSU free responses to the prompts scored, and as other institutions in our twelve institution pilot finish their interventions we need to get the free text scored there as well. If the variance and difficulty of the tests match, we’d like to get it all paired up into a true pre/post, and maybe even compare motion of high-performers to low performers. (Update 2/8/2019: As mentioned above,
The student free text responses were too spotty in terms of length and descriptiveness to reliably quantify changes in strategy, but have provided unique insights into where students went right and wrong which we are applying to curriculum and future assessment design )
But as I look at the data I can’t help but think a lot of what-if fatalism about tribalism and cynicism is misplaced. I’ve talked repeatedly as fact-checking as “tools for trust”, a guard against the cynicism that cognitive overload often produces. I think that’s what we’re seeing here. It makes students more capable of trust.
I’m also just not seeing the knotty education problem people keep talking about. True, much of what we have done in the past — CRAAP, RADCAB, critical-thinking-as-pixie-dust and the like — has not prepared students for web misinformation. But a history of bad curricular design doesn’t mean that education is pointless. It often just means you need better curriculum.
I’ll keep you all updated as we hit this with a bit more data and mathematical rigor.

Leave a comment