One of the problems I’ve had for a while with traditional digital literacy programs is that they tend to see digital literacy as a separable skill from domain knowledge.
In the metaphor of most educators, there’s a set of digital or information literacy skills, which is sort of like the factory process. And there’s data, which is like raw material. You put the data through the critical literacy process and out comes useful information on the other side. You set up the infolit processes over a few days of instruction, and then you start running the raw material through the factory, for everything from newspaper articles on the deficit to studies on sickle cell anemia. Useful information, correctly weighted, comes out the other end. Hooray!
This traditional information/web literacy asks students to go to a random page and ask questions like “Who runs this page? What is their expertise? Do they have bias? Is information clearly presented?
You might even get an acronym, like RADCAB, which allows you to look at any resource and ascertain its usefulness to a task.

Or maybe, if you’re in higher education, you’ll get CRAAP:

I’m a fan of checklists, and heuristics, and I’ve got no problem with a good acronym
But let me tell you what is about to happen. We are faced with massive information literacy problems, as shown by the complete inability of students and adults to identify fake stories, misinformation, disinformation, and other forms of spin. And what I predict is that if you are in higher education every conference you go to for the next year will have panel members making passionate Churchillian speeches on how we need more information literacy, to much applause and the occassional whoop.
But which information literacy do we need? Do we need more RADCAB? Do we need more CRAAP?
In reality, most literacies are heavily domain-dependent, and based not on skills, but on a body of knowledge that comes from mindful immersion in a context. For instance, which of these five sites are you going to trust most as a news (not opinion) sources?





Could you identify which of these sites was likely to be the most careful with facts? Which are right-wing and which are left wing? Which site is a white supremacist site?
It’s worth noting if you were able to make those determinations you did it not using skills, but knowledge. When I saw that big “W” circled in that red field of a flag, for instance, my Nazi alarm bells went off. The mention of the “Illuminati” in source three tells me it’s a New World Order conspiracy site. I know little things, like the word “Orwellian” is a judgmental word not usually found in straight news headlines. I’ve read enough news to know that headlines that have a lot of verbal redundancy (“fabricates entire story falsely claiming”, for example, rather than “falsely claims”) are generally not from traditional news sources, and that the term “Globalist” is generally not used outside opinion journalism and “war against humanity” is pitched at too high a rhetorical level.
We act like there’s skills and a process, and there is, certainly. Asking the right question matters. Little tricks like looking up an author’s credentials matters. CRAAP matters. And so on. But the person who has immersed themselves in the material of the news over time in a reflective way starts that process with three-quarters a race’s head start. They look at a page and they already have a hypothesis they can test — “Is this site a New World Order conspiracy site?” The person without the background starts from nothing and nowhere.
Abstract skills aren’t enough. RADCAB is not enough.
Government Slaves
I first really confronted this when I was helping out with digital fluency outcomes at Keene State about six years ago. One of the librarians there called me into a meeting. She was very concerned, because they ran an information literacy segment in classes and the students did well enough on the exercises, but when paper time came they were literally using sites that looked like this:

She was just gobsmacked by it. She didn’t want to say — “Look, just don’t use the internet, OK?” — but that was what she felt like after seeing this. It was crushing to spend two days talking authority and bias and relevance and the CRAAP test, having the students do well on small exercises, and then having students in the course of a project referencing sites like these. (I should say here that we can find lots of sites like this on the liberal side of the spectrum too, but under the Obama administration these particular sorts of sites thrived. We’ll see what happens going forward from here.)
When I started talking to students about sites like this, I discovered there was a ton of basic knowledge that students didn’t have that we take for granted. That FEMA banner is a red flag to me that this site is for people that buy into deep right wing conspiracies that the Obama Administration is going to round conservatives up into FEMA prison camps. The “Government Slaves” to me is a right-wing trope — not necessarily fringe, but Tea Party-ish at the least. Those sites in the top menu — Drudge, Breitbart, InfoWars, and ZeroHedge — are all a sort of conspiracy spectrum starting with alarmist but grounded (Drudge, ZeroHedge) to full on conspiracy sites (InfoWars). The stars on the side signal a sort of aggressive patriotism, and the layout of the site, the Courier typography, etc., is reminiscent of other conspiracy sites I have seen. The idea that cash/gold/silver is going to be “taken away” by the government is a prominent theme in some right-wing “prepper” communities.
Now we could find similar site on the left. My point here is not about the validity of the site. My point is that recognizing any one of these things as an indicator — FEMA, related sites, gold seizures, typography — would have allowed students to approach this site with a starting hypothesis of what the bias and aims of this site might be which they could then test. But students know none of these things. They don’t know the whole FEMA conspiracy, or that some people on the right feel the government is so strong we are slaves to it. They don’t know the who gold/prepper/cash thing. And honestly, if you start from not knowing any of this, why would this page look weird at all?
The Tree Octopus Problem
When I started looking at this problem in 2010, I happened upon an underappreciated blog post on critical thinking by, oddly enough, Robert Pondiscio.
I say “oddly enough”, because Pondiscio is part of a movement I often find myself at odds with: the “cultural literacy” movement of E.D. Hirsch. That movement contended early on that our lack of common cultural knowledge was inhibiting our ability to discuss things rationally. With no common touchpoints, we might as well be speaking a different language.
The early implementations of that — complete with a somewhat white and male glossary of Things People Should Know — rubbed me the wrong way. And Hirsch himself was a strong adversary of the integrated project-based education I believe in, arguing the older system of studying a wide variety of things with a focus on the so-called “lower levels” of Bloom’s Taxonomy was more effective than project-based deep dives. Here’s Hirsch talking down a strong project-based focus in 2000:
To pursue a few projects in depth is thought to have the further advantage of helping students gain appropriate skills of inquiry and discovery in the various subject matters. One will learn how to think scientifically, mathematically, historically, and so on. One will learn, it is claimed, all-purpose, transferable skills such as questioning, analyzing, synthesizing, interpreting, evaluating, analogizing, and, of course, problem solving—important skills indeed, and well-educated people possess them. But the consensus view in psychology is that these skills are gained mainly through broad knowledge of a domain. Intellectual skills tend to be domain-specific.The all-too-frequent antithesis between skills and knowledge is facile and deplorable. (Hirsch, 2000)
I’ve used project-based learning forever, and my whole schtick — the thing which I’ve being trying to get done in one way or another for 20 years now — is scalable, authentic, cross-insitutional project-based education. I’m looking to scale what Hirrch is looking to dismantle. So Hirsch is a hard pill to swallow in this regard.
But it’s those last three lines that are the core of the understanding, and it’s an understanding we can’t afford to ignore: “[T]he consensus view in psychology is that these skills are gained mainly through broad knowledge of a domain. Intellectual skills tend to be domain-specific. The all-too-frequent antithesis between skills and knowledge is facile and deplorable.”
Robert Pondiscio, who works with Hirsch, shows specifically how this maps out in information literacy. Reviewing the 21st century skills agenda that had been released back in 2009, he notes the critical literacy outcome example:
Outcome: Evaluate information critically and competently.
Example: Students are given a teacher-generated list of websites that are a mixture of legitimate and hoax sites. Students apply a website evaluation framework such as RADCAB (www.radcab.com) to write an explanation for deciding whether each site is credible or not.
Pondiscio then applies the RADCAB method to a popular assignment of the time. There is a hoax site called the Tree Octopus often used by educators — teachers send students to it and have them try to evaluate whether it is real.

Unfortunately, as Pondiscio points out, any quick application of RADCAB or any other “skills only” based heuristic will pass this site with flying colors
The rubric also tells us we are research pros if we “look for copyright information or ‘last updated’ information” in the source. Very well: The tree octopus site was created in 1998 and updated within the last two months, so it must be a current source of tree octopus information. We are also research pros if we ”look for the authority behind the information on a website because I know if affects the accuracy of the information found there.” Merely looking for the authority tells us nothing about its value, but let’s dig deeper. The authority behind the site is the “Kelvinic University branch of the Wild Haggis Conservation Society.” Sounds credible. It is, after all, a university, and one only has to go the extra mile to be a Level 4, or “Totally Rad Researcher.” The Tree Octopus site even carries an endorsement from Greenpeas.org, and I’ve heard of them (haven’t I?) and links to the scientific-sounding ”Cephalopod News.”
If you want to know the real way to evaluate the site, claims Pondiscio, it’s not by doing something, it’s by knowing something:
It’s possible to spend countless hours looking at the various RADCAB categories without getting the joke. Unless, of course, you actually know something about cephalopods — such as the fact that they are marine invertebrates that would have a tough time surviving or even maintaining their shape out of the water — then the hoax is transparent.
And, in fact, when we shake our heads at those silly students believing in the Tree Octopus, we’re not surprised at the fact they didn’t look for authority or check the latest update. We’re disappointed that they don’t understand the improbability of a cephalopod making the leap to being an amphibious creature without significant evolutionary changes. We’re amazed that they believe that long ago a common cephalopod ancestor split off into two branches, one in the ocean, and one in the forest, and they evolved in approximately the same way in polar opposite environments
That’s the weird thing about the Tree Octopus. And that’s what would make any informed viewer look a bit more deeply at it, not RADCAB analysis, not CRAAP, and not some generalized principles.
To Gain Web Literacy You Have to Learn the Web
There’s a second point here, because what a web literate person would actually do on finding this is not blindly go through a checklist, but execute a web search on Tree Octopus. Doing that would reveal a Snopes page on it, which the web literate person would click on and see this:
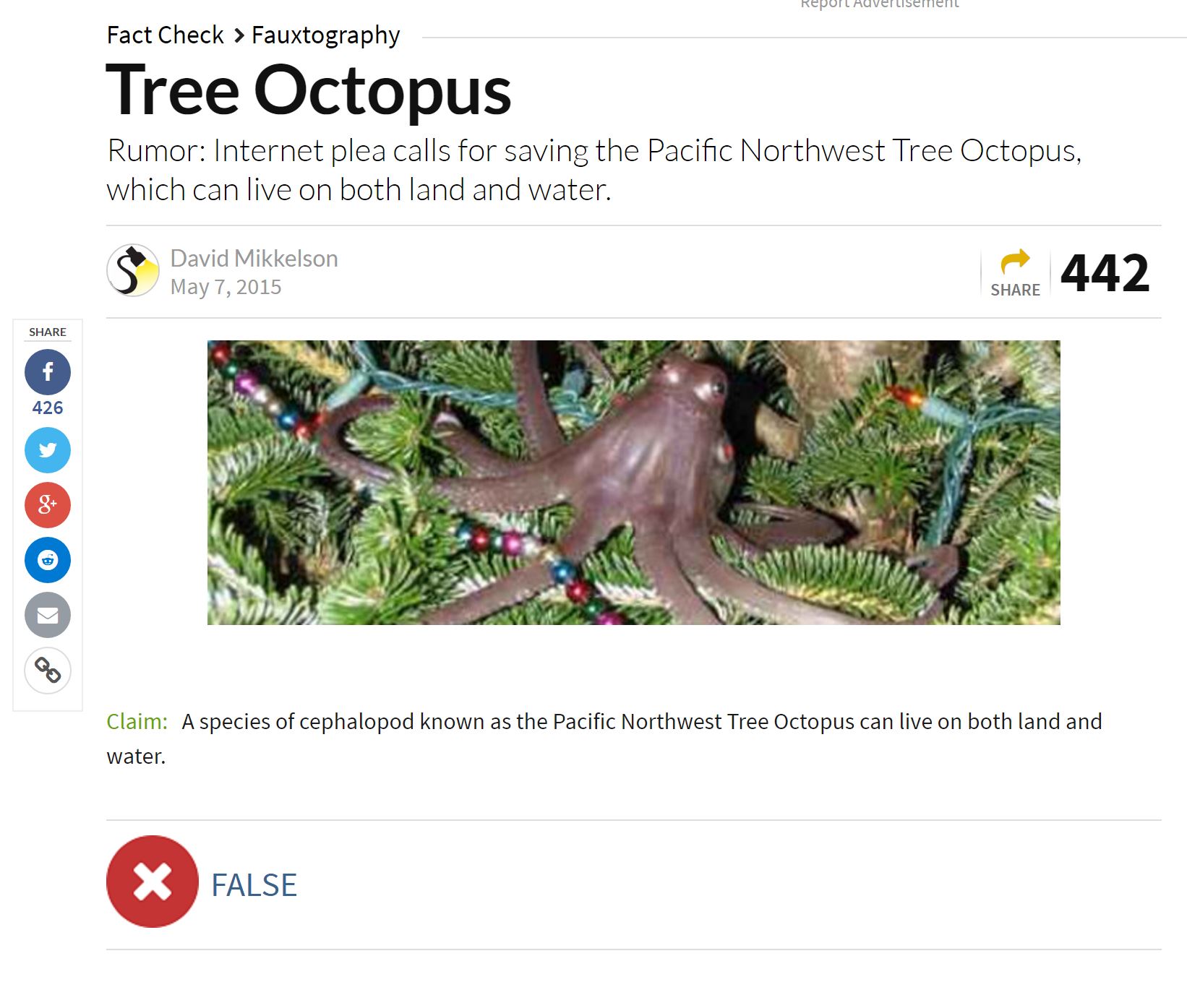
Why would they click Snopes instead of other web search results? Is it because of Relevance, or Currency? Do you have some special skill that makes that particular result stand out to you?
No, it’s because you know that Snopes is historically a good site to resolve hoaxes. If it was a political question you might choose Politifact. If it wasn’t a hoax, but a question that needed answering, you might go to Stack Exchange. For a quote, Quote Investigator is a good resource with a solid history. Again, it’s not skills, exactly. It’s knowledge, the same sort of knowledge that allows a researcher in their field to quickly find relevant information to a task.
But let’s say you went to Wikipedia instead of Snopes. And again, you found it was labelled a hoax there:

Well, to be extra sure, you’d click the history and see if there were any recent reversions or updates, especially by anonymous accounts. This is Wikipedia, of course:

Looking at this we can see that this page has had a grand total of seven characters changed or added in the past six months, and almost all were routine “bot” edits. Additionally we see this page has a long edit history — with hundreds of edits since 2010. The page is probably reliable in this context.
Don’t know what Wikipedia bots are, or what they do? Honestly, that’s a far greater web literacy problem than applying “currency” to Wikipedia articles.
Incidentally, “currency” in our RADCAB rubric gets Wikipedia backwards. If we had arrived at this Wikipedia page in 2010, for example, on February 28th from about 6:31 p.m. to 6:33 p.m. we would have found a page updated seconds ago. But in Wikipedia, that can often mean trouble, so we would have checked “Compare Revisions” and found that minutes ago the assertions the page made were reversed to say that the Tree Octopus was real:
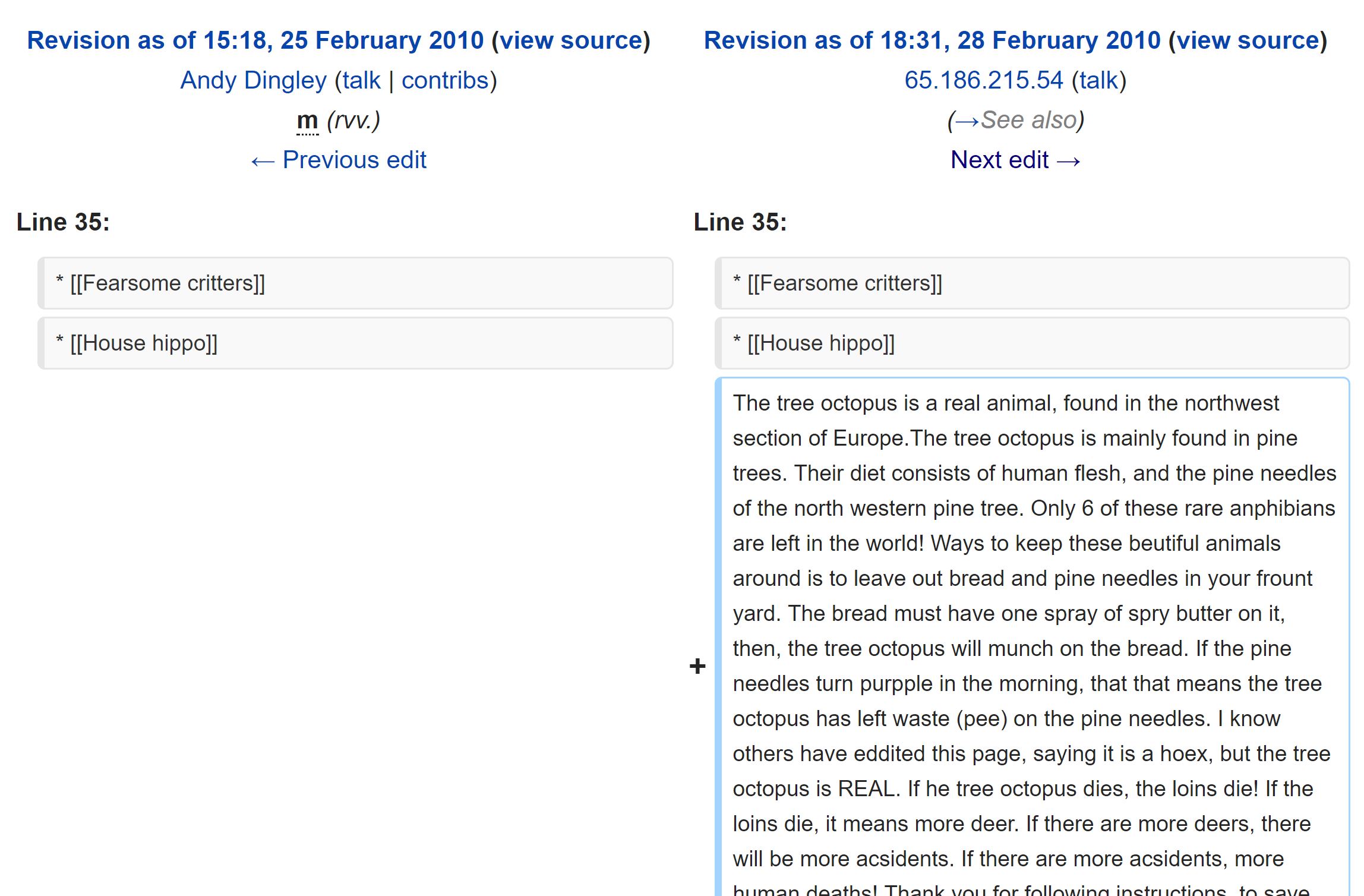
Furthermore, it’s an edit from an anonymous source, as you can tell from the IP address at the top (65.186.215.54). The recency of the edit, especially from an anonymous source, makes this a questionable source at this particular moment.
Incidentally, in a tribute to the efficiency of Wikipedia, this edit that asserts the Tree Octopus is real is up for less than 120 seconds before an editor sees the prank and reverts it.
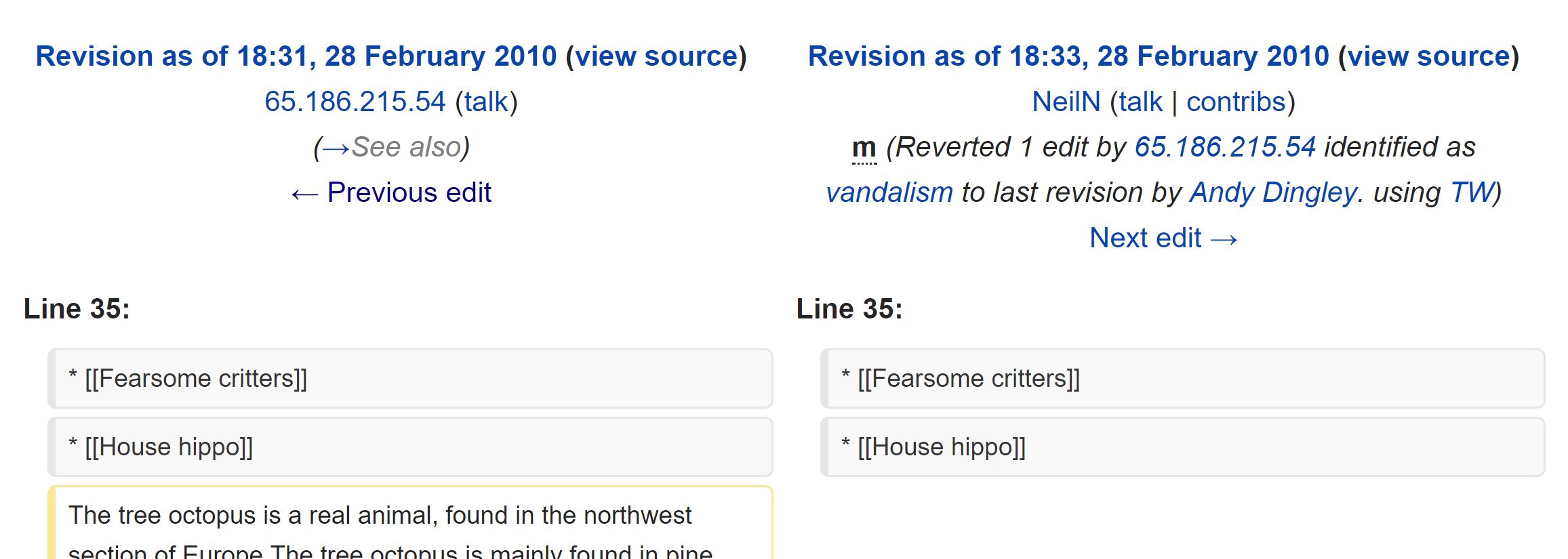
How are you supposed to know this stuff? Edit histories, bots, character counts as an activity check, recency issues in Wikipedia, compare revisions, etc? How are you going to know to choose Snopes over “MyFactCheck.com”?
Through a general skills checklist? Through a rubric?
The radical idea I’d propose is that someone would tell you these things, the secret knowledge that allows web literate people to check these things quickly. That secret knowledge includes things like revision histories, but also domain knowledge — that Snopes is a good hoax checker, and Quote Investigator is a good source for checking quotes. It includes specific hacks to do reverse image searches to see if an image is real, using specific software such as TinEye or Google Reverse Image Search.
Further, the student would understand basic things like “How web sites make money” so they could understand the incentives for lies and spin, and how those incentives differ from site to site, depending on the revenue model.
In other words, just as on the domain knowledge side we want enough knowledge to quickly identify whether news items pass the smell test, on the technical side we don’t want just abstract information literacy principles, but concrete web research methods and well-known markers of information quality on the web.
We Don’t Need More Information Literacy. We Need a New Information Literacy.
So back to those inevitable calls for more information literacy and the inevitable waves of applause.
We do need more education to focus on information literacy, but we can’t do it the way we have done it up to now. We need to come down from that Bloom’s Taxonomy peak and teach students basic things about the web and the domains they evaluate so that they have some actual tools and knowledge to deal with larger questions effectively.
I’ll give an example. Recently there was a spate of stories about a study that found that students couldn’t differentiate “sponsored content” from native content. Many thinkpieces that followed talked about this as a failure of general literacy. We must build our student’s general critical thinking skills! To the Tree Octopus, my friends!
The study authors had a different idea. The solution, they wrote, was to have students read the web like fact-checkers. But to do that we have to look at what makes fact-checkers effective vs. students. Look, for example, at one of the tasks the students failed at — identifying the quality of a tweet on gun control:

As the study authors note, a literate response would note two things:
- The tweet is from Move On, and concerns a study commissioned by Center for American Progress, a liberal think tank, and this may indicate some bias, but
- The poll they link to is by Public Policy Polling, a reputable third party third party polling outfit, which lends some legitimacy to the find.
The undergraduates here did not do well. Here’s how they struggled:
An interesting trend that emerged from our think-aloud interviews was that more than half of students failed to click on the link provided within the tweet. Some of these students did not click on any links and simply scrolled up and down within the tweet. Other students tried to do outside web searches. However, searches for “CAP” (the Center for American Progress’s acronym, which is included in the tweet’s graphic) did not produce useful information.
You see both sides of the equation in this tweet. A fact checker clicks links, obviously. And while that seems obvious, keep in mind it never occurred to half the students.
But the second part is interesting too — the students had trouble finding the Center for American Progress because they didn’t know “CAP”. There’s a technical aspect here, because if they just scoped their search correctly — well, here’s my first pass at a search:

So one piece of this is students need to know how to use search. But the other piece is they need to be able to recognize that we call this policy area “gun control”. That sounds weird, but again, consider that most of these students couldn’t figure that out.
And honestly, if you fact check on the internet long, you’ll end up knowing what MoveOn is and what the Center for American Progress is. Real fact-checkers don’t have to check those things, because any person that tracks these issues is going to bump into a handful of think tanks quite a bit. Learning what organizations like CAP, Brookings, Cato, AEI, and Heritage are about is actually part of the literacy, not a result of it.
Instead of these very specific pieces of knowledge and domain specific skills, what did the students give back to the researchers as method and insight? They gave them information literacy platitudes:
Many students made broad statements about the limitations of polling or the dangers of social media content instead of investigating the particulars of the organizations involved in this tweet.
You see the students here applying the tools that information literacy has given them. Be skeptical! Bias happens! Social media is not trustworthy!
And like most general-level information literacy tools, such platitudes are not useful. They need to know to click the link. They need to know what a think tank is. They need to know how to scope a search, and recognize the common term for this policy area is “gun control”. But we haven’t given them this, we’ve given them high level abstract concepts that never get down to the ground truth of what’s going on.
Fukashima Flowers
You see this time and time again. Consider the Fukashima Flowers task from the same study:
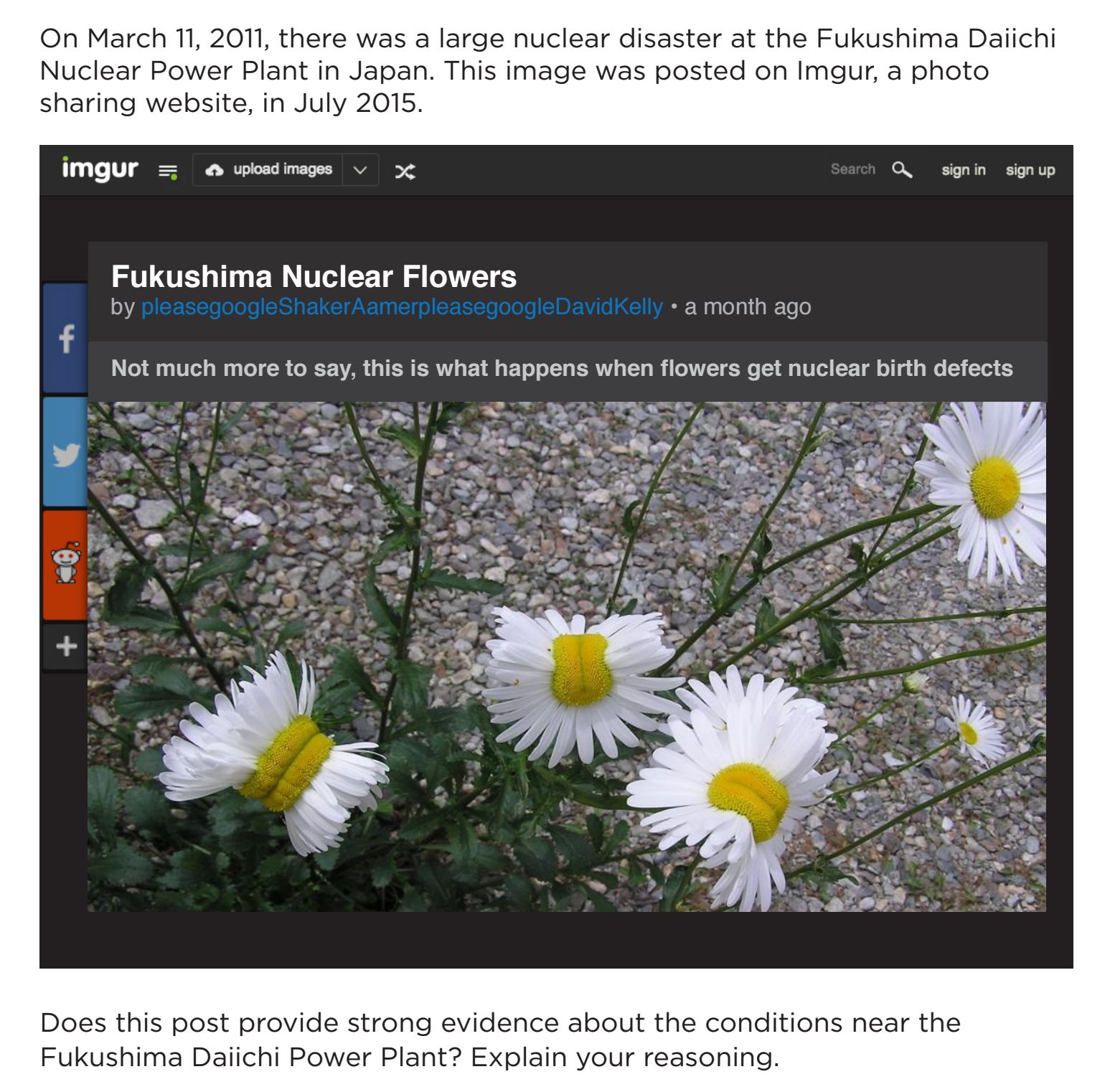
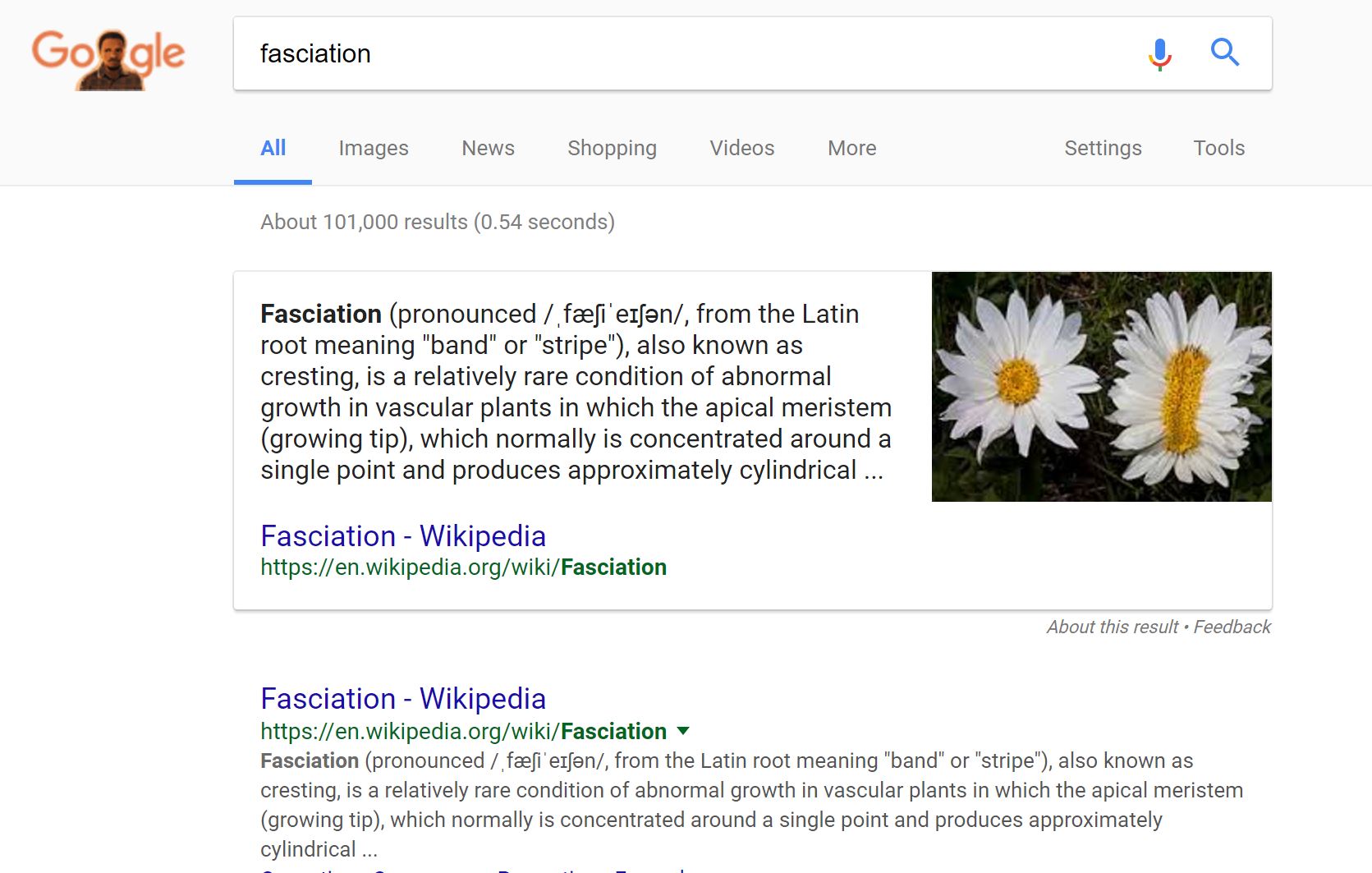
My first thought on this is not “Is this good evidence?” My first thought is “Is this a hoax?” So I go to Snopes:

And there I get a good overview of issue. The photo is real, and it’s from an area around Fukashima. But the process it shows is fasciation, and, while rare, fasciation occurs all around the world.
Do I want to stop there? Maybe not. Maybe I look into fasciation rates and see how abnormal this is. Or maybe I dig deeper into known impacts of radiation. But I’ve already got a better foothold on this by following the admonition “Check Snopes first” than any acronym of abstract principles would give me.
Do the students check Snopes? No, of course not. They apply their abstract reasoning skills, to disappointing results:
On the other hand, nearly 40% of students argued that the post provided strong evidence because it presented pictorial evidence about conditions near the power plant. A quarter of the students argued that the post did not provide strong evidence, but only because it showed flowers and not other plants or animals that may have been affected by the nuclear radiation.
I know Bloom’s Taxonomy has fallen out of favor recently in the circles to which I belong. But this is an extremely good example of what happens when you jump to criticism before taking time to acquire knowledge. The students above are critical thinkers. They just don’t have any tools or facts to think critically with.
Now maybe in another world Snopes doesn’t have this story. I get that you can’t always go to Snopes. And maybe googling “Fukushima Flowers” doesn’t give you good sources. Well, then you have to know reverse image search. Or you might need to know how to translate foreign news sources. Or you might need to get the latest take on the flowers by limiting a Google News search by date.
My point is not that you don’t have to deal with questions of bias, or relevancy, or currency. You’re absolutely going to confront these issues. But confronting these issues without domain knowledge or a toolkit of specific technical resources and tricks is just as likely to pull you further away from the truth than towards it.
What Do Real Fact-Checkers and Journalists Do?
Journalists often have to verify material under tight deadlines. What tricks do they use?
Consider this question: you get a video like this that purports to have taken place in Portland, July 2016, where a man pulls a gun on Black Lives Matter protesters. Is this really from Portland? Really from that date, and associated with that particular protest? Or is this a recycled video being falsely associated with a recent event?
Now this video has been out for a while, and its authenticity has been resolved. You can look it up and see if it was correctly labelled if you want. But when it first came out, what were some tricks of the trade? Do they use RADCAB?
No, they use a toolbox of specific strategies, some of which may encode principles of RADCAB, bit all of which are a lot more specific and physical than “critical thinking”.
Here’s what the Digital Verification Handbook out of the European Journalism Centre suggests, for example, about verifying the date of an event on YouTube:
Be aware that YouTube date stamps its video using Pacific Standard Time. This can sometimes mean that video appears to have been uploaded before an event took place.
Another way to help ascertain date is by using weather information. Wolfram Alpha is a computational knowledge engine that, among other things, allows you to check weather from a particular date. (Simply type in a phrase such as “What was the weather in Caracas on September 24, 2013” to get a result.) This can be combined with tweets and data from local weather forecasters, as well as other uploads from the same location on the same day, to cross-reference weather.
You may not realize this, but rainy and cloudy days are actually quite rare in Portland in July — it rains here for like nine months of the year, but the summers are famously dry, with clear sky after clear sky. Yet the weather in this video is cloudy and on the verge of raining. That’s weird, and worth looking into.
We check it out in Wolfram Alpha:
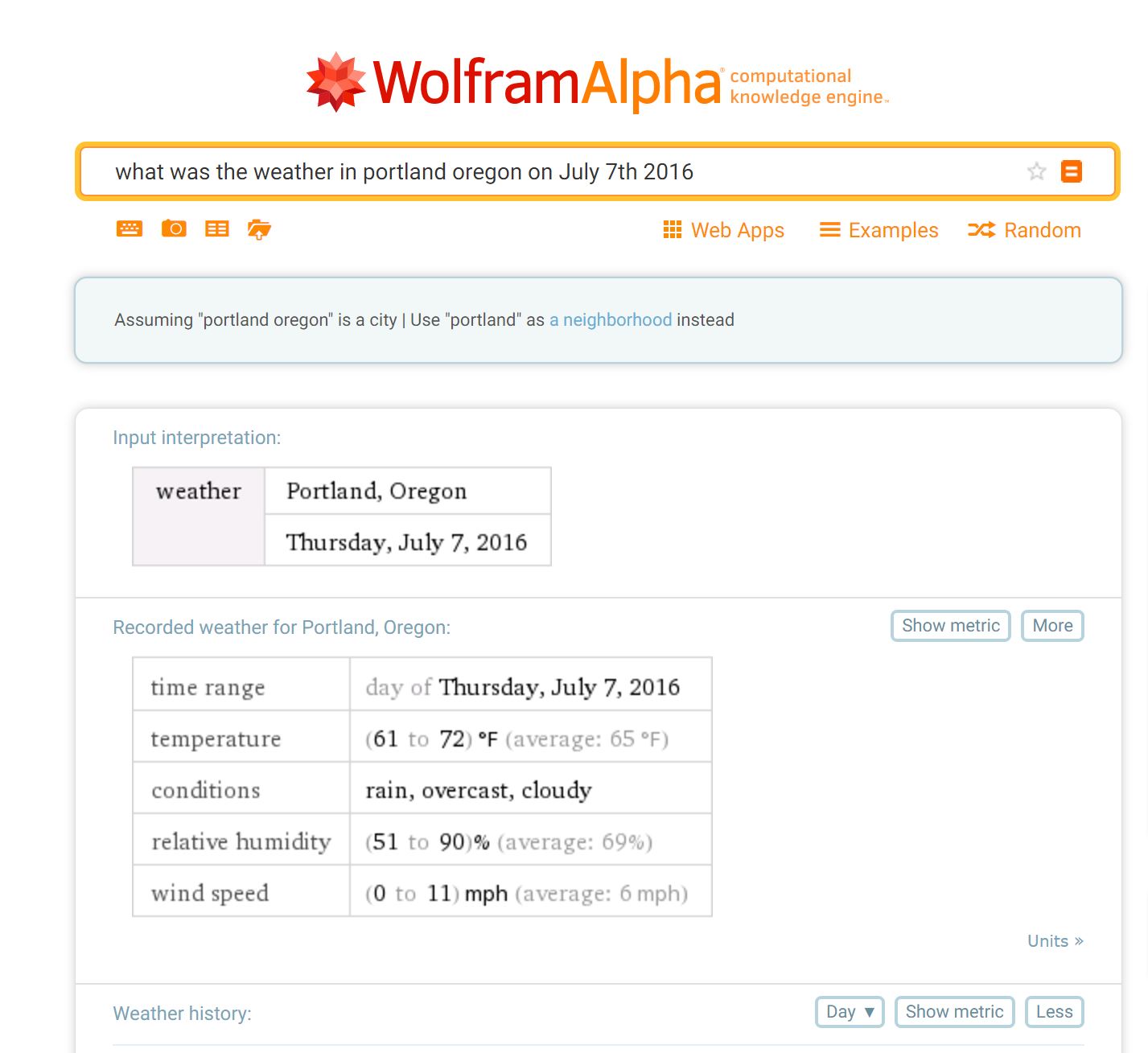
And it turns out the weather fits! That’s a point in this video’s favor. And it took two seconds to check.
The handbook is also specific about the process for different types of content. For most content, finding the original source is the first step. Many pictures (for example, the “Fukushima flowers”) exist on a platform or account that was not the original source, thus making it hard to ascertain the provenance of the image. In the case of the Fukushima flowers did you ever wonder why the poster of the photo posted in English, rather than Japanese, and had an English username?
A web illiterate person might assume that this was game over for the flowers, because what Japanese person is going to have a name like PleaseGoogleShakerAamer?

But as the handbook discusses, this isn’t necessarily meaningful. Photos propagate across multiple platforms very quickly once the photo becomes popular, as people steal it to try to build up their status, or get ad-click-throughs. A viral photo may exist in hundreds of different knock-off versions. Since this is User-Generated Content (UGC), the handbook explains the first step is to track it down to its source, and to do that you use a suite of tools, including reverse image search.
And when we do that we a screen cap of a Twitter image that is older than the picture we are looking at and uses Japanese, which, lets face it makes more sense:

(BTW, notice that to know to look for Japanese we have to know that the Fukushima disaster happened in Japan. Again, knowledge matters.)
Once we have that screen cap we can trace it to the account and look up the original with Google translate on. In doing so we find out this is resident of the Fukushima area who has been trying to document possible effects of radiation in their area. They actually post a lot on information on the photo in their feed as they discuss it with various reporters, so we can find out that these were seen in another person’s garden, and even see that the photographer had taken a photo before they bloomed, a month earlier, which reduces the likelihood that this is a photo manipulation somewhat dramatically:

Even here, the author notes that they know it is a known mutation of such things. And they give the radiation level of that part of Japan in microsieverts which allows you to check it against health recommendation charts.
A month later they check back in on the flowers and post the famous photo. But immediately after they say this:

In other words, three tweets after the famous photo the tweeter gives you the word of what this is called (fasciation) and even though the rest of the text is garbled by the translator that’s a word you can plug into Google to better understand the phenomenon:
So here’s a question: does your digital literacy program look like this? Is it detective work that uses a combination of domain knowledge and tricks of the trade to hunt down an answer?
Or does it consist of students staring at a page and asking abstract questions about it?
It’s not that I don’t believe in the questions — I do. But ultimately the two things that are going to get you an answer on Fukushima Flowers are digital fact-checking strategies and some biology domain knowledge. Without those you’re going nowhere.
Conclusion: Domain-Grounded Digital Literacy That Thinks Like the Web
I didn’t sit down to write a 5,000 word post, and yet I’m feeling I’ve only scratched the surface here.
What is the digital literacy I want?
I want something that is actually digital, something that deals with the particular affordances of the web, and gives students a knowledge of how to use specific web tools and techniques.
I want something that recognizes that domain knowledge is crucial to literacy, something that puts an end to helicopter-dropping students into broadly different domains.
I want a literacy that at least considers the possibility that students in an American democracy should know what the Center for American Progress and Cato are, a literacy that considers that we might teach these things directly, rather than expecting them to RADCAB their way to it on an individual basis. It might also make sense (crazy, I know!) that students understand the various ideologies and internet cultures that underlie a lot of what they see online, rather than fumbling their way toward it individually.
I think I want less CRAAP and more process. As I look at my own process with fact-checking, for example, I see models such as Guided Inquiry being far more helpful — systems that help me understand what the next steps are, rather than abstract rubric of quality. And I think what we find when we look at the work of real-life fact-checkers is that this process shifts based on what you’re looking at, so the process has to be artifact-aware: This is how you verify a user-generated video for example, not “here’s things to think about when you evaluate stuff.”
To the extent we do use CRAAP, or RADCAB, or CARS or other models out there, I’d like us to focus specifically on the methods that the web uses to signal these sorts of things. For example, the “S” in CARS is support, which tends to mean certain things in traditional textual environments. But we’re on the web and awful lot of “support” is tied up in the idea of hyperlinks to supporting sources, and the particular ways that page authors tie claims to resources. This seems obvious, I suppose, but remember that in evaluating the gun control claim in the Stanford study, over half the students didn’t even click the link to the supporting resource. Many corporations, for business reasons, have been downplaying links, and it is is having bad effects. True digital literacy would teach students that links are still the mechanism through which the web builds trust and confidence.
Above all, I just want something that gets to a level of specificity that I seldom see digital literacy programs get to. Not just “this is what you should value”, but rather, “these are the tools and specific facts that are going to help you act on those values”. Not just “this is what the web is”, but “let’s pull apart the guts of the web and see how we get a reliable publication date”. It’s by learning this stuff on a granular level that we form the larger understandings — when you know the difference between a fake news site and an advocacy blog, or understand how to use the Wayback Machine to pull up a deleted web page — these tools and process raise the questions that larger theories can answer.
But to get there, you have to start with stuff a lot more specific and domain-informed than the usual CRAAP.
(How’s that for an ending? If anyone wants a version of this for another publication or keynote, let me know — we need to be raising these questions, and that means talking to lots of people)

Leave a comment