by Mike Caulfield.
Keynote delivered at NWACC 11/6/2014.

Part 1: Sputnik
I’m going to start this keynote by stealing a story from Steven Johnson, a historian of technology.
Johnson uses the invention of GPS as a case study in how innovation happens. It’s his favorite story and he’s told it everywhere from a TED Talk to Science Friday, so apologies if you’ve heard it before. But he repeats it for a reason — it’s just an excellent example of what innovation and progress actually look like.

The way the story goes is this. Sputnik launches in 1957, and America freaks out. The Russians are in space! It’s like Ebola, ISIS, and Gamergate all rolled up in one.
Meanwhile some physicists at Johns Hopkins are hanging out, and wondering — would it be possible to listen to this satellite? It’s sending out a signal, mostly to just show it’s still up there. Kind of like a Space Age Machine That Goes Ping.
So a couple of these guys go and fiddle with microwave receiving equipment — they just want to get this ping on tape. But when they record it, the pings are not the same. They vary slightly. And they realize that this is classic doppler effect stuff — the ping is compressed as the satellite approaches and stretched as it moves away.
And we get really lucky here, because one or another of them says, hey let’s turn this project up to eleven – let’s use the variation of these pings to plot the trajectory of Sputnik around the earth using a mathematical model of the Doppler Effect.
And here’s the part that that interests both me and Johnson, because a couple weeks after this, their boss calls them in. And he’s heard about their project, and he has a question.
He says, if you could calculate the position of the satellite from a set position on the ground, could you calculate your position on the ground from knowing the set position of a satellite?
Because there was this problem he was tasked with — we needed to know the position of nuclear submarines, and astrolabe and a chronometer weren’t going to cut it.
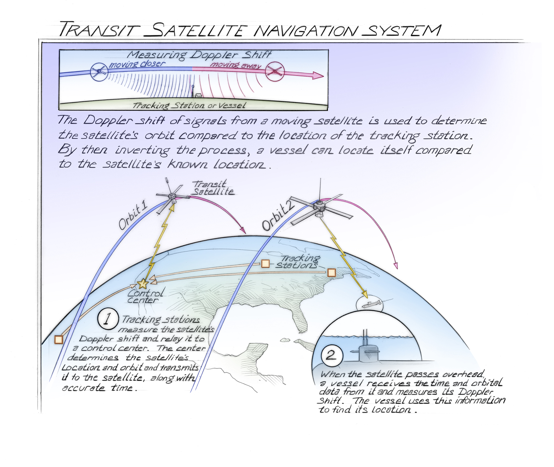
This sequence of events leads to the development of the Transit positioning system by the APL lab at Johns Hopkins and by a little known new entity called DARPA.
You know the rest of the story — we start by using GPS to plot positions of nuclear subs in 1960, but in the 80s and 90s we commercialize the system. We move through a series of inventions to this point in time where the cell phone in your pocket is plotting your position right now, ready to plot your run or clue you into the nearest parking, gas station, or bar.
So that’s Johnson’s story. But here’s another piece of the story that Johnson doesn’t cover.

This is a letter from Arthur C. Clarke, the famous sci-fi author. And besides suggesting communications satellites, he notes that you could put three satellites up in the air and use them to plot your position anywhere on earth using something the size of a watch.
It’s from 1956, a year before Sputnik went up. And it turns out that Clarke had proposed a version of this in 1945.
Now the model is somewhat different than the APL version as we’ll see later — in APL they were using doppler shift with Low Earth Orbit (LEO) satellites. Clarke’s idea involves geostationary satellites in a high earth orbit.
So I’m not saying that Clarke had the full idea here.
Still, nowhere in the history can I find any indication that the people working on this had heard of Clarke’s idea — an idea he had had since WWII.
And ultimately, even if they had, this is just one idea among thousands that never saw the light of day. This is the one where we have a record. Who knows how many other ideas about satellite aided GPS were never captured anywhere?
So one thing we can do is celebrate the environment that actually led to this invention at Johns Hopkins, as Johnson so rightly does.
But what I’m obsessed with (and really, what Johnson is really obsessed with too, in a sense) is how people who wanted to position nuclear submarines were not familiar with Clarke’s proposal.
And my sense is that this sort of thing happens almost every day — someone somewhere has the information or insight you need but you don’t have access to it. Ten years from now you’ll solve the problem you’re working on and tell me about the solution and I’ll tell you — Geez, I could have told you that 10 years ago.
How does this happen? Why does communication break?
One answer to that is right in front of us. This is a letter, addressed to one person who might find it interesting. Clarke couldn’t have addressed it to the folks at APL because he didn’t know they would be interested.
And this is why this concept of “openness” has become the most important concept in the digital world.
You don’t know who can benefit from your information, the modern solution to that is to not even try to guess. Unless there is a compelling reason you should always publish it as openly as possible. If you don’t, and nuclear war breaks out, it’s on you.
Publish company information to everyone in the company. Publish non-confidential information to the entire world.
This is the lesson I think most of you already know. But I think we often stop there, with openness. And I don’t think that’s enough.
We need to look more deeply into this because this is THE problem of our century.
I fervently believe that amazing solutions to so many of our major problems — renewable energy, education, disease — exist out there somewhere, but they are in pieces. You have a piece of the solution and someone in Bangalore has another piece of the solution. And if those ideas find each other in ten years, we’ll save thousands of lives, but if we can help those ideas find each other in ten months, we’ll save millions.
So I want to celebrate our advances in this area, but I also want to critique them. Because it’s worth the effort to do better.
Part 2: The Broken Social Media Spiral

Clarke says something interesting in 2003 about the GPS idea he had had a half century before. He says it was obvious. Anybody in their right mind could have seen it. He didn’t think it was that special an insight.
Carol Goman calls this phenomenon “Unconscious Competence”. You don’t know the value of what you know. It’s not just that Clarke didn’t send his letter to the right people. It’s that Clarke didn’t think there was that much of interest to tell. He sent out that letter, but for the ten years before that that he had had that idea, he didn’t send letters to anyone.
So, we start from this point — knowledge capture — and move forward. The biggest problems of the information age is how we make the most of the massive amount of information we collectively have.
And to make use of it, to really make use of it, a few things have to happen. We have to:
-
record it somewhere
-
route it to the right people
-
extend , organize, localize it
-
pass it back into the streamfor the next iteration
There’s a broad feeling that social media has solved this problem. I think it’s solved a lot of it. But as I think we’ll see, there’s a lot left to improve.

So let’s start with the writing down piece of this, the record, part of what knowledge management people would call externalization. So Jim Groom, for example, was here two years ago giving the keynote, right? Now, Jim and I go back to 2007. We’ve been working and thinking in an area you can call EDUPUNK Connectivism for seven years.
I talk to Jim a lot — and we do it through comments, Twitter, and blog posts that reply to one another.
So what the what the web has done, and blog-like technologies in particular, is move these individual exchanges really quickly to externalization. Ninety percent of what Jim and I have talked about over the years is online, in public, where it’s findable, searchable. Others can benefit from it. Openness combined with these blog-like products — Twitter, Instagram, Pinterest, Tumblr, whatever, makes externalization the default.
That’s progress. To be frank, that’s a TON of progress. But there’s a couple things that makes this approach less than ideal for broad dissemination of ideas.
First, let’s look at the externalization problem. The first problem is that social media tends to get only a certain kind of idea down. Remember Clarke with that letter — it wasn’t just that he didn’t publish it broadly. it was also that he didn’t know it was worth publishing.
These platforms are conversational which makes us overly concerned with publishing interesting stuff.
But here’s the problem — I’m embedded within a pretty advanced group of people in educational technology. Ideas that we think are common might be revolutionary for others. But we’ll never produce posts or tweets about them because everyone in our clan already knows them. And the stuff that we do produce assumes you share our background, so it’s not always readable outside our clan.
And it works the other way too. We’re dumb about a lot of stuff that other folks could teach us a thing or two about. But the chance of that “unconscious competence” reaching us is pretty close to zero.
On the routing stage, I actually think routing goes pretty well on these platforms. I’m amazed at what finds it’s way to me via twitter and blogging.
But the extension piece, that’s an issue. When a blog post from another twitter subculture finds me it’s been routed through all these other nodes. So let’s say an economist publishes something on the String Quartet problem, which is a classic productivity problem that ends up affecting higher ed. I get *some* annotation, right? Someone posts in their stream a link and says something like “This relates to higher ed too”. That’s a helpful prompt.
And maybe that’s enough annotation for me to grok how this obscure economics post relates to my work. Maybe.
But for a nontrivial set of things if information is going to useful to the circles it moves to it is going to need to be recontextualized and reframed. And in a perfect world it would actually be re-edited, wiki style, to foreground the parts that most apply to higher ed and eliminate the pieces that don’t.
A world of compentent extenders would also be a world where we don’t treat these posts like the exhaust of our thought process, thoughts to be expelled as we think them and never returned to. Ideally, when we learn more about an idea we posted several months ago we’d go back and update that post. If I think of a new thing it’s connected to, I’m going to want to write in that new connection.
Extension is where things like wiki have excelled, where communities have worked to extend and connect ideas rather than just retweeting them.
So there’s a composition teacher buried in me — it’s what I did before educational technology. And looking at this I can’t help see the “Kinneavy triangle”.
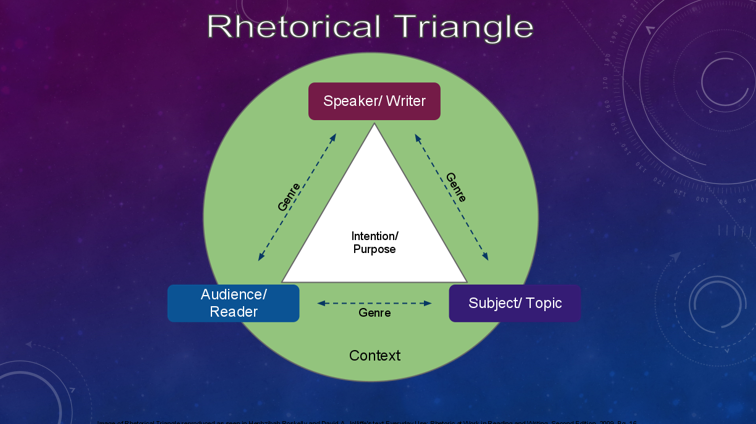
Kinneavy took the speech triangle from lingustics (speaker, listener, referent) and used it to explain composition. You had narrative (I), dialogue/persuasion (focussed on the you), and exposition (focussed on the “it” — what we’re talking about).
And his idea was that you move students through these modes of writing. But I’m interested in this as a sort of lifecycle of information. An idea starts out with what it means to you, the “I” in this situation. Then it pings around a social network and is discussed (the “you” phase). And then in the final phase it sort of transcends that conversation, and becomes more expository, more timeless, less personal, more accessible to conversational outsiders.
When I look at this triangle, it seems to me that different technologies excel at different stages. Things like Evernote and Delicious or Diigo excel at that “I” part. Here you just take notes on what means something to you. And you don’t want it to be dialogic necessarily, because that ends up limiting what you capture. Start out by just caring about yourself, and you’ll actually capture more.
Twitter and blogging, on the other hand, excel at the dialogic and persuasive functions. Ideas ping around and reach unexpected people. Sometimes you even learn something.
For the expository phase, it’s wiki that excels. By cracking open ideas and co-editing them, we turn these time-bound, person-bound comments into something more expansive and timeless. We get something bigger than the single point of view, smarter than any single person.
So one thing I’m interested is how we create a system that allows information to flow in this way. One way might be to link up Evernote, Twitter, RSS Feeds and Wiki in a certain way.
Another way is to start at the end technology — in this case wiki — and look at what it would take to make it work better in the other stages, the I and the You, the personal and the dialogic.
So that’s what I’m going to do today. I’m going to demonstrate a newer technology called federated wiki which allows the sort of communal wiki experience, but also supports those earlier stages of the knowledge life cycle.
Part 3: Kate Middleton’s Dress

So here’s the problem with using wiki for those first two stages. Wiki, as it currently stands, is a consensus *engine*. And while that’s great in the later stages of an idea, it can be deadly in those first stages.
As an example of this, how many of you have heard of the Kate Middleton Wedding Dress Wikipedia fiasco?
OK, so this is fascinating. Here’s how it went down.
There was all this talk before the Kate/William Royal Wedding about the royal wedding dress, which is apparently a big deal. It’s historic.
There’s a whole fascinating history of wedding dresses and monarchs. The white wedding dress that’s such a staple of weddings nowadays? It goes back to Queen Victoria’s wedding dress. Diana’s dress, if you’re old enough to remember those overhead shots of the wedding, had a 25 foot train, which apparently made it really difficult for her dad to sit in the carriage with her on the way to the wedding. Kate Middleton’s dress had more modest nine foot train.
You can see the world in a grain of sand according to William Blake. And wedding dresses are not my thing, but for some people they’re that grain of sand.
So some enterprising person went to Wikipedia and started a page on Kate Middleton’s dress. And she and some others started to build it out.
About sixteen minutes later, someone – and in this case it probably matters that is was a dude – came and marked the page for deletion as trivial, or as they put it “A non-notable article incapable of being expanded beyond a stub”

So all hell breaks loose. You get the pie fight of all pie fights. Here’s the smallest sample of comments on that talk page. These are all just about whether the page has a right to exist.
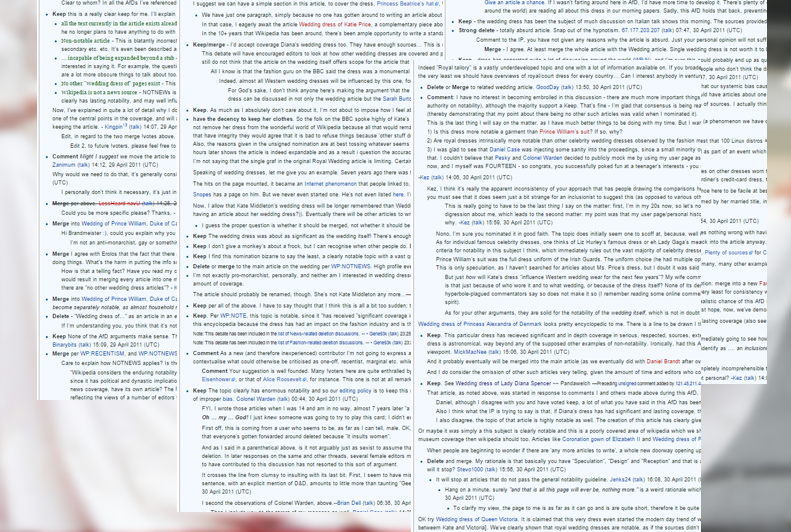
Dress defenders say this is a dress of historical importance. Dress attackers say there’s no other wedding dress pages up. Dress defenders say – are you honestly saying that Wikipedia is defined by what’s NOT in it? Wouldn’t that, taken to its logical conclusion, mean that you couldn’t add anything?
Finally founder Jimmy Wales shows up on the talk page and to his credit says:
Strong keep – I hope someone will create lots of articles about lots of famous dresses. I believe that our systemic bias caused by being a predominantly male geek community is worth some reflection in this context. Consider Category:Linux distribution stubs – we have nearly 90 articles about Linux distrubtions, counting only the stubs. With the major distros included, we’re well over a hundred. One hundred different Linux distributions. One hundred. I think we can have an article about this dress. We should have articles about one hundred famous dresses.–Jimbo Wales (talk) 08:58, 30 April 2011 (UTC)
You can imagine this as a movie moment. A Jimmy Stewart, Frank Capra moment where everyone on Wikipedia looks sheepishly at one another and comes to their senses, right?
Except of course, no. This is Wikipedia, so a bit after this someome replies — to Jimmy Wales, co-founder of Wikipedia — basically, stop being a bleeding heart social justice warrior. You’re driving away all us male geek editors with your “activism”. Ugh.
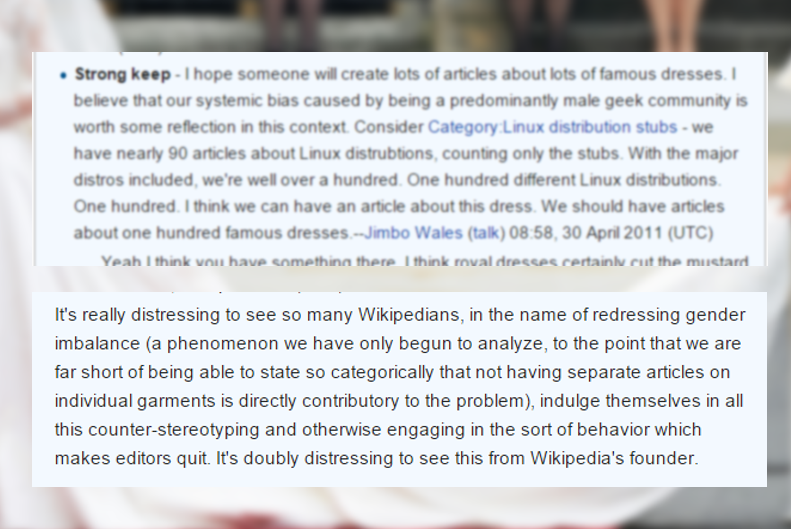
And if you want to know why wiki never got the traction, I think that’s the reason right there.
If you find a community online big enough to be socially interesting it comes with this baggage. You have an idea, you hear a fact, you learn a technique you want to share.
You go online to share it and you’re teleported past the personal and dialogic and suddenly find yourself having to defend the inclusion of this fact or this edit FOR ALL TIME. In many cases, you’re arguing with *pedants*, and even where the conversation stays amicable, is this really how you want to start your day?
And it gets worse, because if you lose that battle (notability, accuracy, citations, linked ideas — whatever the battle is) your contribution disappears. It’s easy to say that it’s all in the revision history, but in practice what Google can’t see does not exist, and Google can’t see that revision history.
Part 4: Introducing Federation

Wiki is a relentless consensus engine. That’s useful.
But here’s the thing. You want the consensus engine, eventually. But you don’t want it at first.
It’s funny, I was looking over this keynote last night, and I saw this line and realized — this is the simplest explanation of federated wiki.
You want the consensus engine, eventually. But you don’t want it at first.
This is a problem. It’s pretty easy to build a system that starts with consensus and then fragments into personal opinion and individual statements. In fact, we build a lot of systems like this accidentally. Entropy can be added rather easily to any system.
It’s harder to build something that starts fragmented and personal, but then organically becomes a shared communal space. You’re looking for a system that produces what Polanyi called “spontaneous order”.
So back in February I saw a video of Ward Cunningham, the initial inventor of both wiki and really of wiki culture — he was the first wiki admin as well, and many of the conventions of wiki come out of his unique take on how collaboration fails and how it succeeds.
And what he says in this presentation is we end up being pushed to consensus in these systems because we’ve got the technology upside down. Here’s a slide to show what he means by that.
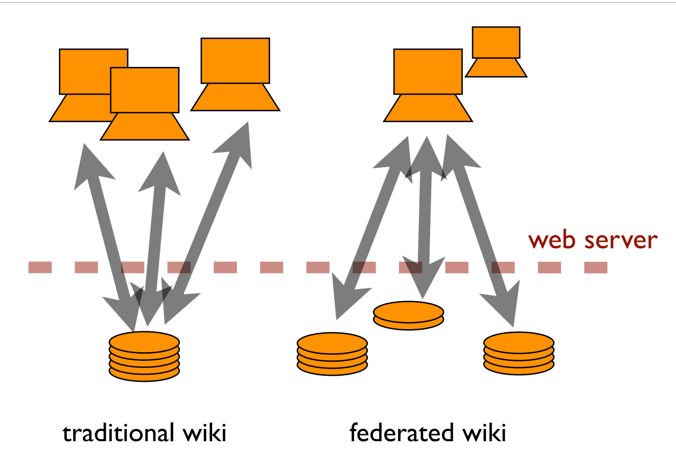
In a traditional wiki, you have multiple people sharing a single server, and the server is the ultimate arbiter of what’s on the wiki. In a federated wiki, everyone has their own server which stores the records associated with them. But the meaning is made in your browser. Your browser pulls wiki records from all over the internet, and makes them look like they exist on a single server.
If you have a background in network theory, I think you’ll see immediately at how this inversion creates a sort of evolutionary ecosystem where we reach consensus not through arguing who gets to control a page on a specific server, but by seeing which versions of a page spread to where.
If you don’t have a background in network theory, I want you to forget this slide, and just watch what I’m going to do next. In my entire time talking about this I’ve found almost no one gets the massiveness of the architectural shift at first — I don’t want you to understand it, I just want you to know it’s there.
Ultimately, the theory is that this thing here is the “spontaneous order” engine that can move from the fragmented to the unified.
Either that hypothesis is right or wrong. My job here is not to argue a side of that hypothesis — it’s to convince you this is an hypothesis worth testing.
Again, if you don’t completely get this idea, don’t worry. The view from the user side is much simpler.
Part 5: Arthur C. Clarke Uses Federated Wiki

So I want to sketch out what life looks like if Arthur Clarke had federated wiki in say 1950, which we’ll guess at as a time when this GPS idea came about.
Incidentally, if I happen to be wrong and APL did know about Clarke’s idea, you can replace references here to GPS with communications relays, satellite phones, home computers, or any of the dozen major predictions Clarke envisioned years before they happened.
In our scenario, Clarke keeps a journal, and one day he thinks:
If three geosynchronous satellites were in orbit they could ping you the time. By measuring the different delays of the pings you could calculate how far you were from each satellite and triangulate your position.
The following video shows how that might look.
Important: The video contains the next two minutes of the presentation — the presentation won’t make sense without it.
So that’s the capture and linking side of things. We jot down idea, write reactions to readings, organize our own thoughts. Over time, we connect them, like a personal Memex.
The next stage is that routing we talked about — how do ideas spread? In this video we show you how Clarke’s idea spreads through copies in a decentralized way that requires no central service.
Important: The video contains the next two minutes of the presentation — the presentation won’t make sense without it.
And then, finally, *really* neat things happen. Clarke has recorded his ideas and linked them. Readers like Maria have propagated those ideas by follow a fork-to-like convention. When they finally reach a physicist working on a similar issue we move to dialogue and eventually the extension of the resource. Again, the network here does not just route the pages; the pages are expanded and extended by the nodes they touch.
Important: The video contains the next three minutes of the presentation — the presentation won’t make sense without it.
And there we are. We’ve moved from the personal, to the dialogic, to the expository. We’re working on resources and ideas together rather than thumbs-up or thumbs-downing. Kind of lovely, right?
Part 6: Academic Uses
(Here we walked through class examples and personal examples, mostly demonstrating how students move through a similar progression, from the I to the You to the It. It was unplanned and driven by audience questions, and I don’t have a transcription.)
Conclusion

I don’t have much of a conclusion here, actually. If I’ve done my job, you should be either excited about this, or absolutely terrified. Either is fine, actually.
As long as you’re not complacent.
I’m hoping we can talk about this. Some possible applications. I can share where the fedwiki team is with it.
I’m hoping I get some allies. Maybe you’re all allies.
But even if you’re not, I hope this can open up an honest discussion about the ways in which social media is not serving our needs as it currently stands. As advocates we’re so often put in a situation where we have to defend the very idea that social media *is* an information sharing solution that we don’t often get to think about what a better solution for collaboration would look like. Because there are problems with the way social media works now.
My hypothesis is that this federated scheme solves many of the problems. I might be right.
But what I *know* I’m right about is that these problems exist, and they are serious.
Minority voices are squelched, flame wars abound. We spend hours at a time as rats hitting the Skinner-esque levers of Twitter and Tumblr, hoping for new treats — and this might be OK if we actually then built off these things, but we don’t.
We’re stuck in an attention economy feedback loop that doesn’t allow us silent spaces to reflect on issues without news pegs, and in which many of our areas of collaboration have become toxic, or worse, a toxic bureaucracy.
We’re stuck in an attention economy feedback loop where we react to the reactions of reactions (while fearing further reactions), and then we wonder why we’re stuck with groupthink and ideological gridlock.
We’re bigger than this and we can envision new systems that acknowledge that bigness.
We can build systems that return to the the vision of the forefathers of the web. The augmentation of human intellect. The facilitation of collaboration. The intertwingling of all things.
This is one such proposal. Maybe you have others.
Let’s talk.


Leave a comment