There’s a follow-up to this article, now, which explains the federated wiki angle to this more clearly..
“Everyone here will of course say they are carrying on his work, by whatever twisted interpretation. I for one carry on his work by keeping the links outside the file, as he did.” – Ted Nelson, eulogizing Doug Engelbart.
1.
When people talk about Vannevar Bush’s 1945 article As We May Think, they are usually talking about the portion that starts around section six, which seems so prescient:
The owner of the memex, let us say, is interested in the origin and properties of the bow and arrow. Specifically he is studying why the short Turkish bow was apparently superior to the English long bow in the skirmishes of the Crusades. He has dozens of possibly pertinent books and articles in his memex. First he runs through an encyclopedia, finds an interesting but sketchy article, leaves it projected. Next, in a history, he finds another pertinent item, and ties the two together. Thus he goes, building a trail of many items. Occasionally he inserts a comment of his own, either linking it into the main trail or joining it by a side trail to a particular item. When it becomes evident that the elastic properties of available materials had a great deal to do with the bow, he branches off on a side trail which takes him through textbooks on elasticity and tables of physical constants. He inserts a page of longhand analysis of his own. Thus he builds a trail of his interest through the maze of materials available to him.
But the problem is that it is not prescient. Not at all. The web works very little like this.
Let’s look at some of the attributes of the memex.
You have a library of items. You own them, they are in your memex. You don’t link documents you have to documents you don’t, because that would be silly. Bret Victor has talked about this eloquently elsewhere.
Each memex library contains your original materials and the materials of others. There’s no read-only version of the memex, because that would be silly. Earlier in the article Bush goes through great pains to show that the “dry photography” necessary to users adding their own writings is possible. And your writings are first class citizens of the library, being browsed and linked by the same interface responsible for showing you the works of Shakespeare, Einstein, or Claude Levi-Strauss.
Links are associative. This is a huge deal. Links are there not only as a quick way to get to source material. They remind you of the questions you need to ask, of the connections that aren’t immediately evident.
Links are made by readers as well as writers. A stunning thing that we forget, but the link here is not part of the author’s intent, but of the reader’s analysis. The majority of links in the memex are made by readers, not writers.
Links are outside the text. A corollary perhaps of the above, but since links are a personal take by readers on the relationships of two items, the links cannot be encoded in the document, because that enforces a single interpretation of the document. Links inside the document say that there can only be one set of associations for the document, which would be silly.
There are both linear trails and side trails. This may be weird to our modern sensibilities, but clearly Bush has scenarios in mind where you’d follow a more or less linear reading path, and scenarios where you’d have a lot of side paths.
Going further into the document:
And his trails do not fade. Several years later, his talk with a friend turns to the queer ways in which a people resist innovations, even of vital interest. He has an example, in the fact that the outraged Europeans still failed to adopt the Turkish bow. In fact he has a trail on it. A touch brings up the code book. Tapping a few keys projects the head of the trail. A lever runs through it at will, stopping at interesting items, going off on side excursions. It is an interesting trail, pertinent to the discussion. So he sets a reproducer in action, photographs the whole trail out, and passes it to his friend for insertion in his own memex, there to be linked into the more general trail.
…
Wholly new forms of encyclopedias will appear, ready made with a mesh of associative trails running through them, ready to be dropped into the memex and there amplified. The lawyer has at his touch the associated opinions and decisions of his whole experience, and of the experience of friends and authorities…
The historian, with a vast chronological account of a people, parallels it with a skip trail which stops only on the salient items, and can follow at any time contemporary trails which lead him all over civilization at a particular epoch. There is a new profession of trail blazers, those who find delight in the task of establishing useful trails through the enormous mass of the common record. The inheritance from the master becomes, not only his additions to the world’s record, but for his disciples the entire scaffolding by which they were erected.
So publications do sometimes come with pre-made trails, but these are just one set of trails amongst those of you and your friends. And in this lovely utopian flourish, there develops a class of people (“trail blazers”) who go through the records and add new links, new trails, new annotations. I don’t just get to read Alan Kay’s work — I get to see what occurs to Kay as he reads the work of others. Or maybe the best trail blazers are not the Alan Kay’s of the world at all. Maybe there’s a class of people who are great readers, but lousy writers the same way there are great DJ’s who are lousy musicians. We could benefit from their brilliance and textual insights.
2.
What was so exciting about these sections of As We May Think when I first read them was this idea of a new way of transferring knowledge — not by exposition or commentary, but by *linking*. By extending. Trail-blazing.
But this memex thing isn’t how the Internet works. There is no class of trail blazers. You don’t share a set of linked documents with a friend. You don’t own the documents you read. Links are boring references to supporting material, not prompts for though or a model of expert thinking.
Why? I increasingly think that Ted Nelson gets it right. It’s partly about where the links live. To people who have only known hypertext on the web, this may be a difficult thing to wrap ones head around, but let’s do a bit of history.
Early hypertext did not have links as we know them now, the text-embedded “hot-linked” words that cause your mind to pause and ask, “Do I need to click that to understand this?” In fact, links as imagined by the heirs of Bush — Nelson, Van Dam, etc — formed a layer of annotation on documents that were by and large a separate entity.
The “hot spot” link we know today first appeared in the HyperTIES system in the 1980s, almost 15 years after the early hypertext systems of Andy van Dam and Douglas Engelbart. To demonstrate the difference that made in pre-web systems, here’s a mockup of the KMS interface, one of the more advanced hypertext platforms of the 1980s:
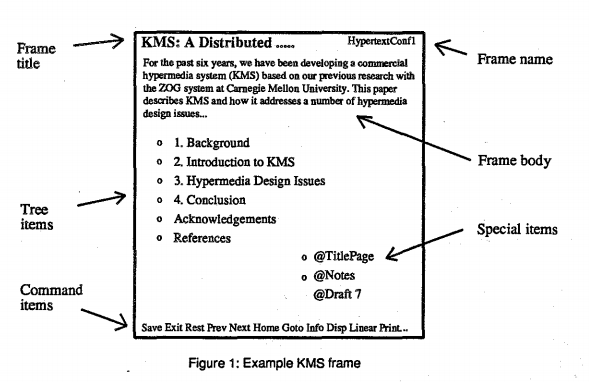
You’ll notice that the tree item links and the special item links are distinct portions of the document.
HyperTIES simplified that design and flattened it, mixing links with text.

The brilliance of this HyperTIES design is immediately evident. By mixing links with text you can have your cake and link to it too. The text reads like regular text, prints like regular text, and can be written by copy-editors as more or less regular text. You can take old manuals, and link them up, more or less as is.
The brillance was not lost on Berners-Lee as he designed the web. In his 1989 proposal he specifically mentions the power of highlighted phrases:
“…several programs have been made exploring these ideas, both commercially and academically. Most of them use “hot spots” in documents, like icons, or highlighted phrases, as sensitive areas. Touching a hot spot with a mouse brings up the relevant information, or expands the test on the screen to include it. Imagine, then, then references in this document, all being associated with the network address of the thing to which they referred, so that while reading this document you could skip to them with a click of the mouse.”
That phrasing is really telling: “Imagine, then, then references in this document,” he says, imagine them being hyperlinked so you could go directly to them. Imagine hyperlinking existing documents to references already in this document…
It’s genius. But it’s also a very author-centric version of linking, and one which is not going to reveal to you anything the author didn’t already know.
More importantly it does something unintentionally evil — for any given document there can be only one valid set of relationships, inscribed by the author. So you can link your history of the Polaroid ID-2 camera up to suit the engineering people, or to suit the history of corporate boycotts people, but you can’t set it up the links serve both without overlinking the crap out of it.
3.
Federated wiki deals with this issue by keeping links within the document but letting every person have as many copies of that document as they like, with whatever links they want on each. It’s a simple solution but in practice it works quite well.
What I’ve been interested in however (and something that MC Morgan has been looking at as well) is the way in which writing in federated wiki pushes people to a new way of thinking about links and content.
I’m going to decribe my own evolving behavior here, but I’ve seen similar progressions with most people who have used federated wiki.
In the newer style, content is kept fairly short, and fairly link-less. But at the bottom of the articles we annotate by linking to other content with short explanations of each link. Here’s the bottom of a page on how Kandinsky came up with the idea of abstract art after seeing an unrecognizable painting on its side:

Here’s another bottom of a page on the concept of “Gradually, then Suddenly” — the idea that things tend to decline slowly over a long period of time and then one day, just as people think the decline is livable, the bottom falls out all at once:

What is interesting about this method is it plays into something else we saw in the federated wiki happenings. We expected people to edit each other’s documents a lot, and they did some of that. But what people liked to do most was add links and notes at the bottom to related pages, or, in many cases, create a new page specifically to be linked from the old. The pattern was something along the lines of “Oh, this article reminds me of something I could bring to the table, let me add a link and write that page.”
It reminded me of storytelling sessions where you tell a story in response to my story, and somehow those two stories juxtaposed tell a bigger, fuzzier truth. But it gets better — because of the federation mechanisms, when you add links you add them on your own copy of a page. People seeing your links can choose accept or reject them. Good and useful connections can propagate along with the page. I mentioned ages ago (was it really only November?) that as federated wiki pages move through a system they are improved, and that’s true. But the more common scenario is that as they move through a system they are connected.
And this makes a certain sense after all. If I write a page on early community antennas as the origin of cable the chances that you’re a cable history expert who can improve it are rather low. But the chance that you know something related, perhaps in your own area of expertise, are rather high. And the connections I’ve found through others have often been amazing. (One of those connections, Hospitable Hypertext, has become a core insight for me. And if you go to that page you’ll see an early attempt at conversation by linking at the bottom, before we found our stride).
I’m at kind of a loss at how to end this, but it’s been in my queue long enough. So I’m putting it out. Apologies if it’s a bit muddled, these are very much thoughts in progress…

Leave a comment