Via @roundtrip, this conversation from July: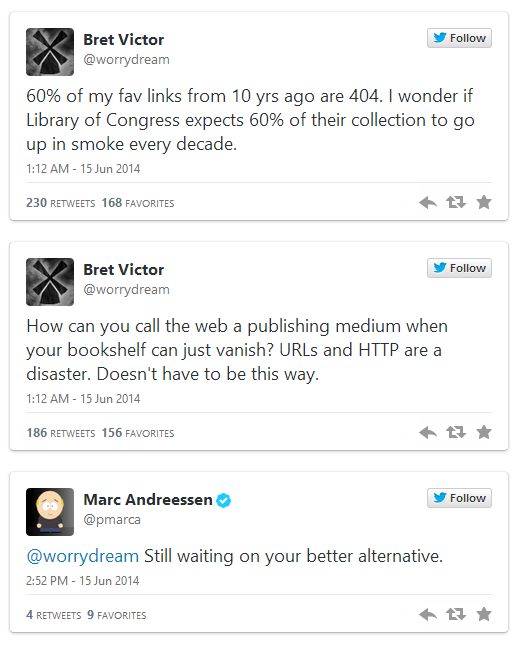
There’s actually a pretty simple alternative to the current web. In federated wiki, when you find a page you like, you curate it to your own server (which may even be running on your laptop). That forms part of a named-content system, and if later that page disappears at the source, the system can find dozens of curated copies across the web. Your curation of a page guarantees the survival of the page. The named-content scheme guarantees it will be findable.
It also addresses scalability problems. Instead of linking you to someone’s page (and helping bring down their server) I curate it. You see me curate it and read my copy of that page. The page ripples through the system and the load is automagically dispersed throughout the system.
It’s interesting that Andreessen can’t see the solution, but perhaps expected. Towards the end of a presentation I gave Tuesday with Ward Cunningham about federated content, Ward got into a righteous rant about the “Tyrrany of Paper”. And the idea he was digging at was this model of a web page as a printed publication had caused us to ignore the unique affordances of digital content. We can iteratively publish, for example, and publish very unfinished sorts of things. We can treat content like data, and mash it up in new and exciting ways. We can break documents into smaller bits, and allow multiple paths through them. We can rethink what authroship looks like.
Or we can take the Andreessen path, which as Ted Nelson said in his moving but horribly misunderstood tribute to Doug Englebart, is “the costume party of fonts that swept aside [Englebart’s] ideas of structure and collaboration.”
The two visions are not compatible, and interestingly it’s Andreessen’s work which locked us into the later vision. Your web browser requests one page at a time, and the layout features of MOSAIC>Netscape guarantee that you will see that page as the server has determined. The model is not one of data — eternally fluid, to be manipulated like Englebart’s grocery list — but of the printed page, permanently fixed.
And ultimately this gives us the server-centric version of the web that we take for granted, like fish in water. The server containing the data — Facebook or Blogger, but also WordPress — controls the presentation of the data, controls what you can do with it. It’s also the One True Place the page shall live — until it disappears. We’re left with RSS hacks and a bewildering array of API calls to accomplish the simplest mashups. And that’s because we know that the author gets to control the printed page — its fonts, its layout, its delivery, its location, its future uses.
The Tyrrany of Print led to us gettting pages delivered as Dead Data, which led to the server-centric vision we now have of the web. The server-centric vision led to a world that looked less like BitTorrent and more like Facebook. There’s an easy way out, but I doubt anyone in Silicon Valley wants to take it.

Ward Cunningham’s explanation of federation (scheme on right) — one client can mash together products of many servers. Federation puts the client, not the server, in control.
UPDATE:
It seems we got front-paged at Hacker News. So for those that don’t follow the blog I thought I’d add a one minute video to show how Smallest Federated Wiki uses a combination of JSON, NodeJS, and HTML5 to accomplish the above model. This vid is just about forking content between two different servers, really basic. Even neater stuff starts to happen when you play with connecting pages via names and people via edit journals, but leave that to another day.
This and more videos and explanations are available at the SFW tag.

Leave a comment