ONE IMPORTANT NOTE: I’m just toying with this idea, not asserting it at this point. But part of me is very interested in what happens when we view the rise of the app as not a betrayal of the original vision of the web, but as a potential return to it. I don’t see many people pushing that idea, so it seems worth pushing. That’s how I roll. 😉
——-
Apropos of both an earlier post of mine and Jim’s Internet Course. This is a screenshot of the first web browser (red annotations added by me):

The first web browser was a storage-neutral editing app. If you pointed it at files you had permission to edit, you could edit them. If you pointed it at files you had permission to read, you could read them. But the server in these days awas a Big Dumb Object which passed your files to a client-side application without any role in interpreting them.
I never used the Berners-Lee browser, but even in the mid-90s when I was hacking my first sites together Netscape had a rudimentary editor (I was using something called HoTMeTaL at the time, but stilll):
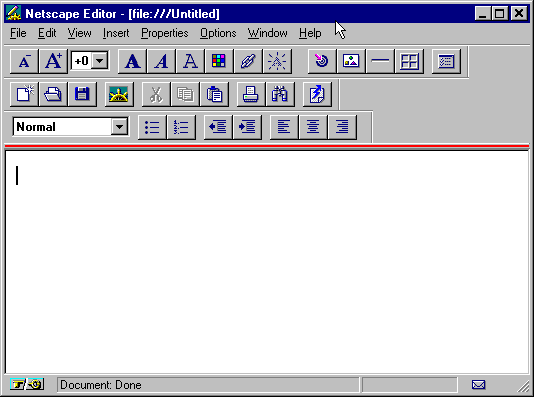
This is still the case with many HTML files a browser handles, but what’s notable here is that in those days a browser sort of worked much like what a storage neutral app would today. When I talk about having the editing functions of a markdown-wiki client-side in an app, we’re essentially returning to this model.
And think about that for a minute. Imagine what that wiki would be like — you tool around your wiki in your browser editing these Markdown files directly. When someone hits your site in their browser, it lets them know that they should install the Markdown extension, or download the Markdown app to view these things. Grabbing a file is just grabbing a file.
So what happened to this original vision? So many things, and I only saw my little corner of the world, so I’m biased.
- Publishers: The first issue hit when the publishers moved in. They wanted sites to look like magazines. This accelerated a browser extension war and pushed website design to people slicing up sites in Adobe and Macromedia tools.
- Databases + Template-based Design: As layouts got more complex, you wanted to be able to swap out designs and have the content just drop in; so we started putting pages in database tables that required server interpretation (this is how WordPress, Drupal, or alomost any CMS works for example).
- Browser incompataibility, platform differences: People didn’t update browsers for years, which meant we had to serve version and platform specific HTML to browsers. This pushed us further into storing page contents in databases.
- E-commerce. You were going to have a database anyway to take orders, so why not generate pages?
- Viruses and Spyware. Early on, you used to download a number of viewer extensions. But lack of a real store to vet these items led to lots of super nasty browser helper objects and extensions, and the fact that you used your browser for e-commerce as well as looking at Pixies fan sites made hijacking your browser a profitable business.
In addition, there was this whole vision of the web as middleware that would pave the way to a thin-client future free from platform incompatibilities. Companies like Sun were particularly hot to trot on this, since it would make the PC/Mac market less of an issue to them. Scott McNealy of Sun started talking about “Sun Rays” and saying McLuhanesque things like “The Network is the Computer“.
In the corporate environment, thin clients are wired to company servers.
In your home, McNealy envisions Sun Rays replacing PCs.
“There’s no more client software required in the world,” he said. “There’s no need for [Microsoft] Windows.”
Sun Rays fizzled, but the general dynamic acclerated. And part of me wonders is it accelerated for the same reasons that Sun embraced it. In a thin client world, the people who own the servers make the rules. That’s good — for the people who own the servers.
This is really just a stream of conciousness post, but really consider that for a moment. In the first version of the web you downloaded a standard message format with your email client, and web pages were pages that could live anywhere (storage-neutral) and be interpreted by a multitude of software (app-neutral). In version two, your mail becomes Gmail, and your pages get locked into whatever code is pulling them from your 10 table database. And yes — your blogging engine becomes WordPress.
OF COURSE there were other reasons, good reasons, why this happened. But it’s amazing to me how much of the software I use on a daily basis (email, wikis, blogs, twitter) would lose almost nothing if it went storage neutral — besides lock-in. And such formats might actually be *more* hackable, not less.
It’s also interesting to see how much other elements of the ecosystem have solved the problems that led us to abandon the initial vision. Apps auto-update now. The HTML spec has stabilized somewhat, and browsers are more capable. The presence of stores for extensions gets rid of the “should I install random extension from unknown site” problem — people install and uninstall apps constantly. Server power is now such that most database-like features can be accomplished in a file-based system — Dokuwiki is file based, but can generate RSS when needed and respond to API calls. And, interestingly, we are finally returning to a design minimalism that reduces the need for pixel-based tweaking.
In any case, this post is a bit of a thought experiment, and I retain the right to walk away from anything I say in it. But what if we imagined the rise of apps as a POTENTIAL RETURN to the roots of the web, a slightly thicker, more directly purposed client that did interpretation on the client-side of the equation? Whether that interpretation is data API calls or loading text files?
I know that’s not where we are being driven, but it seems to me it’s a place that we could go. And it’s a narrative that is more invigorating to me than the “Loss of Eden” narrative that often hear about such things. Just a thought.

Leave a reply to Alexis Silver Cancel reply